Designing Cloud Native Apps With Twelve–Factor


We regularly listen to people using Cloud Native and Cloud terms interchangeably and we challenge that! Cloud Native is about how applications are created and deployed, not where. As Joe Beda, Co-Founder of Kubernetes said:
“Cloud native is structuring teams, culture, and technology to utilize automation and architectures to manage complexity and unlock velocity.”
Cloud Native patterns allow us to design applications with loosely coupled services, being small, independent units each of them addressing a specific problem. Also, our teams can abstract away the underlying infrastructure dependencies and focus on application code. Cloud Native Development enables scalable, highly available, easy-to-manage and more resilient applications.
At xgeeks, our teams leverage Cloud Native patterns to help teams become high performant shortening Lead Time For Change driven by customers’ feedback to improve the application continuously.
Of all the benefits, one we highlight is scalability. The flexibility to up-scale and down-scale resources on demand without application downtime can prevent service disruptions coming from traffic spikes while optimizing the utilization/cost ratio. This is possible because Cloud Native applications are designed to scale horizontally, distributing loads across multiple server instances of the application. However, new cloud adopters face many challenges. Now, the application is part of a distributed system.
We will show you how we solve these challenges with the Twelve-Factor App.
Twelve-Factor App
The Twelve-Factor App is a methodology that was created in 2012 by a group of engineers at Heroku. It consists of a set of twelve practices for building cloud-native apps. The Twelve-Factor App manifesto can be checked here. Even after all the developments achieved in the cloud native landscape and tooling since the creation of the manifesto, these factors remain very present nowadays.
With a Twelve-Factor App, we can design horizontally scaled applications at the infrastructure level, simplifying the orchestration of distributed components and managing resources to scale apps dynamically.
The following describes each twelve-factor and shows, based on our perspective, how each factor can be implemented to accomplish scalability, elasticity, and portability.
I. Codebase
One codebase tracked in revision control; many deploys.
In terms of scalability and elasticity of the application deployment, a properly designed application can mean the difference between a one-month and one-day lead time. By considering the codebase as a source-code repository or a set of repositories with a common root, this principle states that one codebase per application is recommended and can be deployed across multiple environments (Dev, Test and Production).
There is only one codebase per app, but there will be many deploys of the app. A deploy is a running instance of the app.
At xgeeks, we recommend less mature teams start with a Gitflow branching strategy. Funnily, this is controversial since one can say Gitflow is not really compliant with Twelve-Factor App and makes Continuous Integration and Continuous Delivery (CI/CD) harder with long-lived feature branches and multiple primary branches. Although, when we are dealing with projects from scratch and teams are heterogeneously composed in terms of maturity, our primary concern is to have a high level of control over the balance of changes introduced with the speed of development keeping the Change Failure Rate controlled. Using Gitflow, visibility and control are enforced, allowing senior developers to invest more time in code review and mentoring.
If there are multiple codebases, it’s not an app — it’s a distributed system. Each component in a distributed system is an app, and each can individually comply with twelve-factor.
As we mentioned before, we believe that applications should be just small enough independent units. This architecture model makes applications easier to scale and faster to develop.
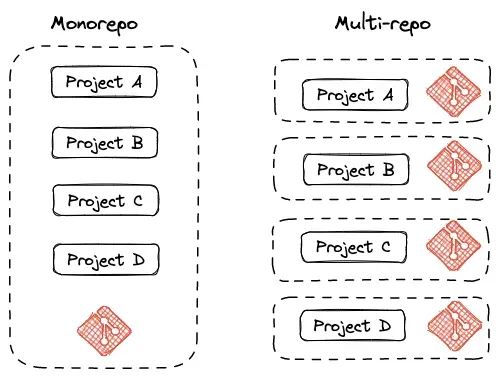
Based on our experience, we typically recommend adopting a multi-repo approach with one repository per application, instead of a mono repo with multimodule projects within a single repository. This approach has proven to be more effective in establishing clear logical boundaries from application to infrastructure level between applications. It also simplifies communication and collaboration within heterogeneous teams who are eager to embrace a DevOps mindset.
By utilizing separate repositories for each application, teams can more easily manage and comprehend the relationships between different components. This approach facilitates the implementation of DevOps practices, as it promotes autonomy and clear ownership over individual applications and their corresponding infrastructure.
II. Dependencies
Explicitly declare and isolate dependencies.
From past experience supporting a customer moving from on-prem to the cloud, we faced the typical issue described below.
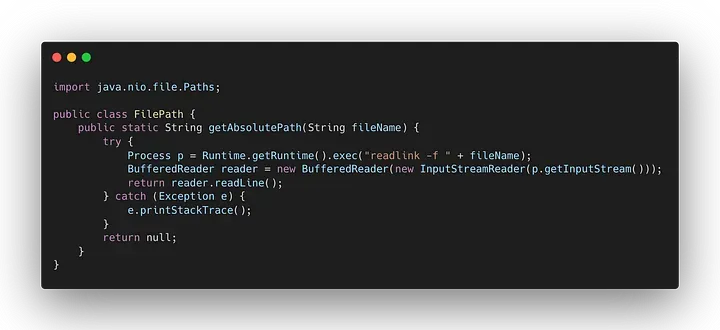
The codebase is explicitly using the readlink syscall to obtain the absolute path of a local file. Moving the code to the cloud was causing an outage since the readlink syscall was not available in the underlying operating system the customer needed to use.
A twelve-factor app never relies on implicit existence of system-wide packages.
To overcome issues like this, application dependencies should be defined in a dependency manifest managed by a dependency manager. Declaring them in a manifest helps teams understand the application and simplifies setup for upcoming developers. In addition, tools like Dependabot and Blackduck can be added to improve security software supply chains from external third-party dependencies.
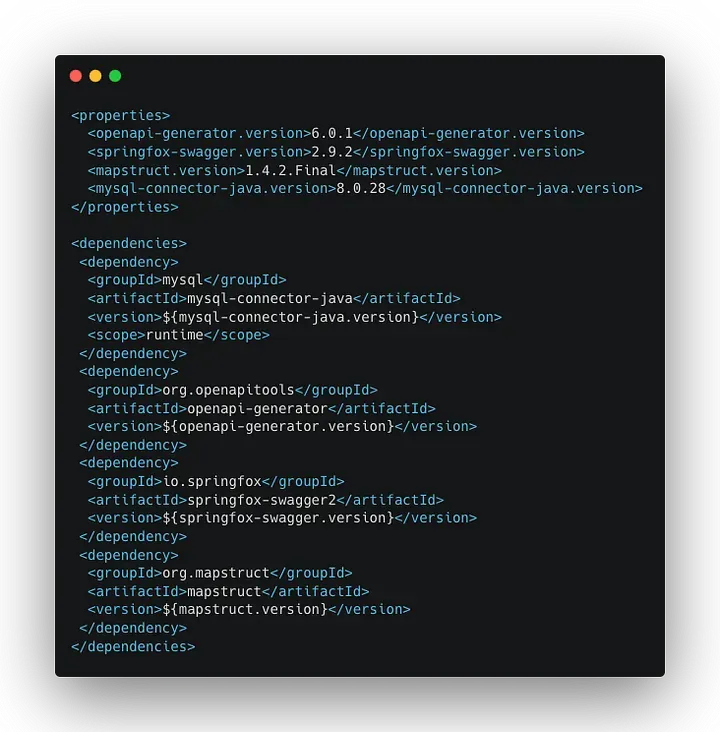
On JVM stacks, our teams usually work with Maven, where dependencies are declared in a pom file, like the one below. Packages are downloaded from the Maven Central Repository at build time.
Containers have decreased dependency-based issues preventing implicit dependencies from “leaking in” from the surrounding system. Nevertheless, one should apply dependency declaration and dependency isolation together, only one will not satisfy the Twelve-factor requirements.
III. Configuration
Store configuration in the environment.
A Twelve-Factor App should separate configurations from code. Configurations such as database connections, credentials for external services, and others, vary substantially across deployments, whereas code does not.
In a twelve-factor app, env vars are granular controls, each fully orthogonal to other env vars. They are never grouped together as “environments”, but instead are independently managed for each deploy.
Storing configurations in environment variables or a configuration file provides flexibility and reduces downtime risk during deployments. Rapidly changing configurations based on the environment becomes possible without recompiling or redeploying code. As a result, deployment and configuration processes can be automated and repeated, leading to scalable and streamlined applications.
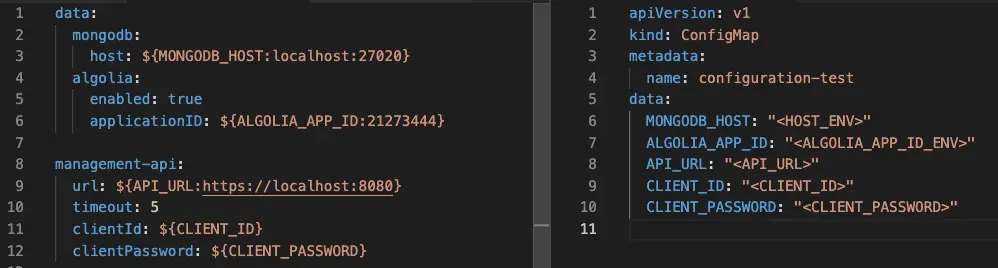
In projects where we use Kubernetes as a container orchestrator, we use ConfigMaps to apply this factor. ConfigMaps are framework and programmatically agnostic, that easily enable application configuration switching between environments.
Consider the next image. The left side represents a configuration file, a application.properties for a Spring application. On the right side, there is ConfigMap. After the app is packed into a container, the ConfigMap file will be applied to the container according to the environment, overwriting the default variables.
Regarding the application credentials, Kubernetes also provides a way to store sensitive information using Secrets. However, to enhance the security (data encryption and identity-based access) and management of secrets, we recommend combining it with a secret management tool like Hashicorp Vault.
IV. Backing Services
Treat backing services as attached resources.
A backing service is a service that the app consumes as part of its normal operation such as databases, messaging/queuing systems, caching systems, etc. Our teams treat backing services as abstractions and don’t differentiate between local and third-party systems. Defining services with a clean contract leverages consumption through an interface (API).
Conversely, our code should not be coupled with any specific backing service implementation. For example, if the application needs to communicate with a database, the code should be agnostic and abstract from all implementations, independent of the database type and vendor. This is very important to treat backing services as attached resources.
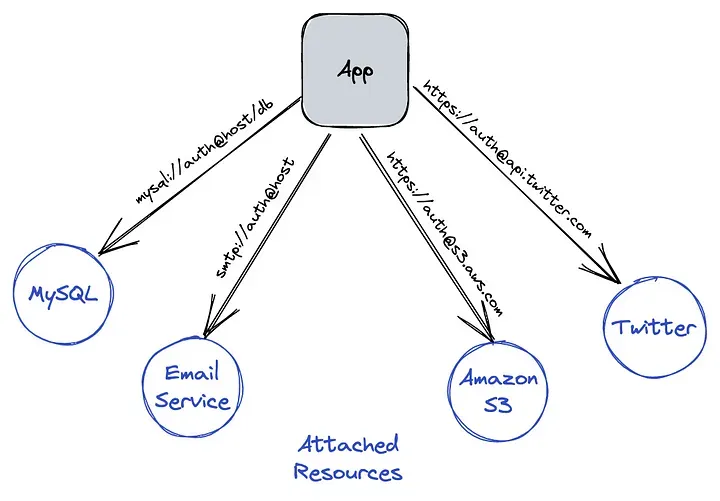
Having applications that are able to access attached resources gives us the capability, at the deploying phase, to switch, for example, from a local MySQL database to a managed database like Amazon RDS, without changing any code. Achieving scalability and flexibility as the system grows. This is only possible if we access resources via URL, abstract the code and keep the endpoints and credentials in a configuration file.
In this way, considering again the ConfigMap example illustrated in the Configuration factor, MongoDB and Algolia are backing services. And, if the app’s database is misbehaving due to a hardware issue, you just need to spin up another database. This is done by changing the environment variable MONGO_DB to the updated server endpoint in ConfigMap, without code changes.
V. Build, Release, Run
Strictly separate build and run stages.
This principle takes the deployment process down into three replicable stages: Build, Release, and Run.
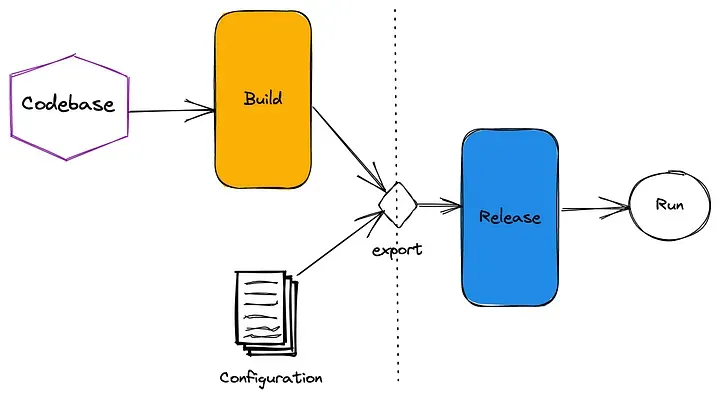
The codebase is taken through the build stage, transforming the source code with its dependencies into a bundle known as a build. The result of the build phase combined with the environment configuration produces a release. Then, the release is deployed into the execution environment and run.
The explicit separation between build and release steps is crucial for sane deployments and rollbacks. At xgeeks, we achieve separation through artifact management — after the code is merged and tested, each build result (image or binary) should be versioned, published and stored in an image registry. We use a private Docker registry for container images and Harbor for Helm charts. This allows releases to be re-used and deployed across multiple environments. If something goes wrong, we can audit the release in a given environment and, if necessary, rollback to the previous one. Ideally, this process is fully automated and doesn’t require human intervention.
VI. Processes
Execute the app in one or more stateless processes.
Cloud Native applications should be volatile and highly disposable. Due to this, a Twelve-Factor App never relies on local storage contents, either on a disk or in memory, being available or that any request will be handled by the same process.
Twelve-factor processes are stateless and share-nothing.
Applications should be executed as one or more stateless processes. Meaning that all long-living states must be external to the application, provided by a backing service, like a database and cache. Applications create and consume a temporary state during a request or transaction. In the end, all data should be destroyed. As a result, the concept of statelessness does not mean that state cannot exist, it means that applications cannot maintain it.
Session state is a common scenario for building web applications we may need to deal with. It captures the status of the user interaction, keeping a session for each user as long as he is logged in. In this way, apps can know recent actions and user personalization, for example. In this specific example using data caching, through Redis, to store these states and ensure nothing is stored locally is an option.
VII. Port binding
Export services via port binding
If we think in a non-cloud environment, we often stumble into scenarios where web apps are executed inside a webserver container. Then the container assigns ports to applications when they start up.
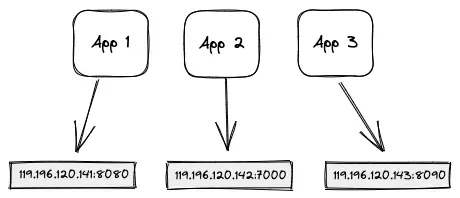
In contrast, Cloud Native apps are self-contained, with a web server library bundled into them, not requiring runtime injections of external containers. In light of this, self-contained services should make themselves available to other services by port-binding — a specific port number defined to listen to requests.
In addition, the port number should be defined as an environment variable (Configuration principle). In this way, we can apply port-binding per environment without changing code.
This factor has been a standard practice for some time but has been enforced by containerization standards, proxies, and load balancer implementations. It is only possible with network mapping between the container and host. Like so, Kubernetes has built-in service discovery and you can abstract port bindings by mapping service ports to containers. Service discovery is accomplished using internal DNS names. Although there are different service types in Kubernetes (you can check here), in the below example, we provide an example of a ClusterIP service.
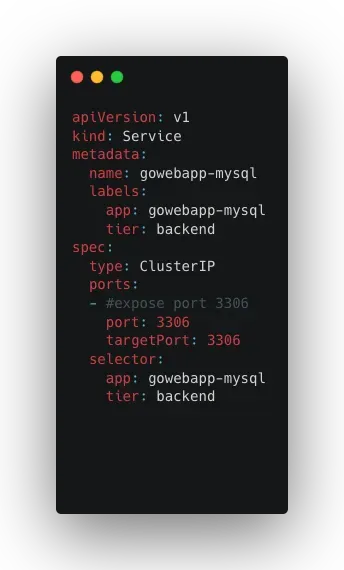
VIII. Concurrency
Scale out via the process model.
This principle recommends organizing processes by their purpose and dividing them into groups to handle workloads efficiently. By architecting applications to handle workloads by process type, teams can manage resources based on each workload. As a result, multiple distributed processes can scale independently. The key to achieving this is to define disposable, stateless and share-nothing processes that can scale horizontally.
At xgeeks, we handle this factor using two approaches that can be combined, Load Balancers and Horizontal Pod Autoscaling (HPA). Regardless of the method, we need to monitor the performance and resource usage of the application to ensure that it remains responsive and performant under heavy loads.
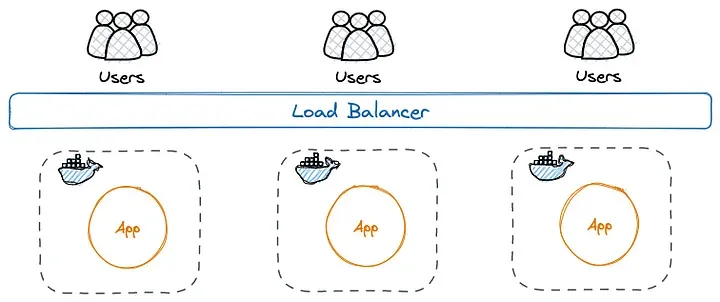
- Load Balancers
Using a load balancer, traffic can be distributed across multiple application instances, preventing the overload of a particular instance.
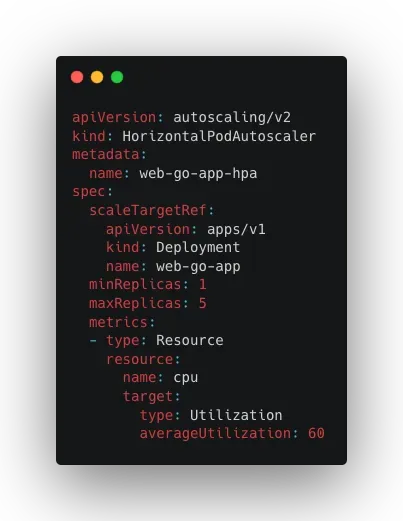
- Horizontal Pod Autoscaling
In projects where we use Kubernetes, our teams take advantage of Horizontal Pod Autoscaling to scale up or down the number of pods running in the cluster based on standards, such as average CPU utilization, average memory utilization, or custom metrics. The following yaml file shows how to configure HPA for web-go-app deployment.
IX. Disposability
Maximize robustness with fast startup and graceful shutdown
We argue that for an application to be robust and scalable, it is essential to have fast startup times, be responsive and have graceful shutdowns. Containers already provide fast startup times. However, it does not solve all problems. It is central to defining start-up and health checks to ensure systems are operating and to rapidly replace any failing instances.
Think of the scenario where a web app is connected to a database as a backing service. At startup, it needs to load some data or configuration files. After deployment, the app starts up and appears ready to receive requests. But… what about the database? Is the database up and prepared to receive connections?
At xgeeks, we adopt monitoring and alerting tools like Prometheus and Datadog. By establishing alerts based on metrics, logs and thresholds, our teams can have more visibility over the systems. Also, we can detect when an instance of your application is misbehaving or experiencing issues and automatically spin up an additional instance to replace it. This is important to prevent long periods of downtime that cost our clients money.
Another approach in our projects is implementing start-up and health checks by defining Kubernetes Liveness and Readiness probes. Considering the previous web app scenario, we can configure a readiness probe to check if the database container is ready to accept traffic. For that, we just need to configure readinessProbe, like the following example, at the container spec level.
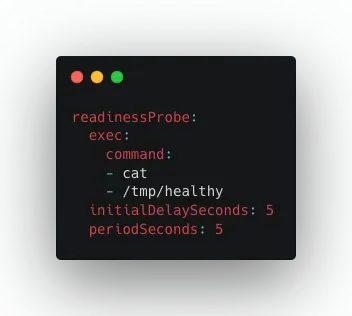
The same care and attention are needed during shutdown. In a graceful shutdown, we can listen for a SIGTERM signal. After that, the web app shuts down the service port, closes its database connections, and flushes its log files. If we disclose the shutdown in a distributed system, it can lead to cascading effects on other systems that rely on it. This can eventually affect customers.
X. Dev/Prod Parity
Keep development, staging and production as similar as possible.
This factor focuses on the importance of keeping development, staging and production environments similar. It is essential to find and catch issues before advancing to production, eliminating the stereotypical development statement, “It runs on my laptop”.
We know that minimal divergence between development and production environments is “normal”. In complex systems, this factor may be one of the most challenging to implement, often because of budget constraints. However, it is critical, to enable speed as organizations scale.
Containers help us mitigate this risk by providing a uniform environment for running code. Tools like Docker can spin up the necessary containers to build and run the application and any dependencies. Also, having an effective CI/CD pipeline can ensure that the same build and deployment steps are executed in all environments. This factor can also be applied by using Terraform, an Infrastructure as a Code tool, by easily replicating environments.
XI. Logs
Treat logs as event streams.
We believe that having a proper logging strategy, metrics and traces is crucial to understanding and managing systems as they evolve and become more complex due to their distributed nature.
A twelve-factor app never concerns itself with routing or storage of its output stream.
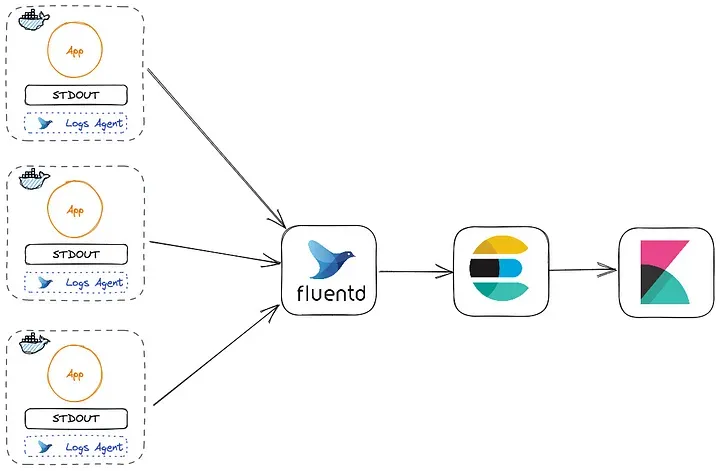
Cloud Native applications can make no assumptions about the file system on which they run, other than the fact it's ephemerality. Logs should be written to stdout and stderr and treated as event streams. Decoupling the aggregation, processing and storage of logs from the app’s core logic, in our vision, empowers elastic scalability. Being the application decoupled from log knowledge, we can easily change the logging approach without modifying the application.
At xgeeks, we use Fluentd as a key player in our logging strategy. Fluentd is an open-source project under the Cloud Native Computing Foundation (CNCF), that acts as a logging agent that manages log collection, parsing and distribution. Further, it can be complemented with ElasticSearch, to store and index JSON documents and, finally, Kibana, for data visualization and discovery. Those tools together are known as the EFK stack. Fluentd is typically deployed on Kubernetes as a DaemonSet that collects all container logs at the cluster level.
XII. Admin Processes
Run admin and management tasks as one-off processes.
Management or administrative tasks are short-lived processes. Such tasks include migrating databases, running one-time scripts, etc. We believe that these types of tasks should be handled separately from application processes. However, they should run on identical systems like an app running in a production environment. Also, such tasks should be tested and reviewed, like the codebase, to avoid synchronization issues.
For Cloud Native apps, this factor becomes more relevant when creating repeatable tasks. In this way, our teams handle management tasks through CronJobs. It empowers scalability and elasticity since tasks are handled inherently by Kubernetes which creates ephemeral containers based on the need for those tasks.
Final Thoughts
Cloud Native development presents a multitude of challenges that require careful consideration. Our aim is to provide valuable insights into the implementation of Twelve-Factor App principles, enabling you to construct systems that are scalable, portable, and reliable. By prioritizing code modularity and containerization patterns, you can pave the way towards achieving horizontal scaling, a crucial capability for high-performing teams seeking to leverage the cloud effectively.
With our perspective and guidance, you can navigate the intricacies of Cloud Native development and harness its full potential. By embracing modularity in your codebase and adopting containerization practices, you will establish a foundation for building scalable systems. This empowers your team to operate within clear boundaries and leverage the power of the cloud, resulting in enhanced performance and growth.