Event–Driven Architecture


As engineers, we are sometimes faced with architectural challenges when trying to anticipate the long-term needs of a business. This is especially tough in a hyper-scaling environment, as we sometimes need to plan for the unknown, we just know the business is growing at a very fast pace, and this means we’ll need to prepare for unforeseen challenges.
In this type of engineering environment, there are a couple of options we can follow to structure our architecture and teams in this article we’re going to delve deeper into one of the possible patterns, event-driven architecture.
In this architecture, a system reacts to specific events or changes in the environment and triggers corresponding actions. The system is built around a set of loosely coupled services that communicate with each other through the use of events. The services are isolated from one another, which allows them to evolve and scale independently. This allows for a highly scalable and responsive system, where services can react to changes and events in real time.
This pattern shines brighter in distributed tech environments, where responsibilities are distributed across multiple teams, which need to communicate between them while also giving space for the birth of other future teams to partake in these communication channels, which makes it ideal for a hyper-scaling company, where the future is not always fully predictable, and where we have to plan for a larger, and not always known, dimension.
Our scenario
In this article we will talk about one of our past experiences, an engineering ecosystem of over 400 engineers working on the same product, a large-scale e-commerce platform with a huge logistics and operations component to acquire, prepare, re-sell and deliver its products, all of this powered by internal and external facing web applications that integrate with multiple 3rd party services. The engineers working on this project were split into vertical teams of around 10 people each, each team fully owning the pieces of software they worked on, from conception all the way down to development and maintenance.
One of these teams is responsible for the management of the life cycle of third-party contracts between the client and the company, namely, extended warranties and insurance. The management of these contracts meant synchronizing information with multiple other external teams, an example of this would be informing the CRM team to handle customer communication when these contracts change state.
One good practical application of event-driven communication is this cross-team sync, especially if it is not time-critical. After a customer purchases a product there are multiple stages before it gets delivered, so most of the work needed to fulfil the order can be done asynchronously. In fact, since some of these stages involve third-party work, sometimes it would actually be beneficial to introduce some delay to ensure systems are able to create their artefacts and have them ready for others to pick up. As such, multiple teams (e.g.: finance, logistics, operations, etc…) would be working in parallel on different verticals to move the order to a finalized state.
In this specific case, the solution was fully architected based on AWS artefacts to provide the cloud computing capability it required. We used Event Bridge to receive, filter, transform, route, and deliver events between different applications/teams, Lambda functions to consume these events and CloudWatch for monitoring and alerting.
Advantages over synchronous API calls
One of the biggest advantages of events is that we can easily track the entire life cycle of an entity (usually orders), including all actions and systems it went through. This provides a clear and easy-to-understand view of the entity’s progress.
As mentioned previously, most of what we needed to do was not time-critical, so synchronous API calls were not needed, or even ideal, as a team would not block the progress of another one that is not directly dependent and would just wait for exactly what it needs. One advantage of this is that if one of the teams requires more time to handle specific operations (like waiting for third-party services) or to recover from a failure when processing the event on their end, it would not block teams from doing what they needed to do and all this work could be run in parallel.
Additionally, it’s very simple to just re-trigger the same event globally in case something goes wrong, or re-running the lambda processing the event in a specific team that might have had a temporary issue. In order for this to work, there are a few conditions that have to be met, for example:
- Each listener has to be able to process the event at any given time;
- Each team would have to implement fault tolerance, by logging any errors that occur while trying to process an event and enabling the team to react to it and fix any issues in order;
- Each event processor would have to ensure idempotency, being able to detect and ignore duplicate events.
This architecture greatly contributes to the stability and scalability of the project as each team can listen to the events they need and trigger their actions accordingly. This decoupling gives teams more freedom and makes it easier to maintain, improve and extend the system as a whole.
The following pictures exemplify the same flow for a created order in synchronous and asynchronous architectures.
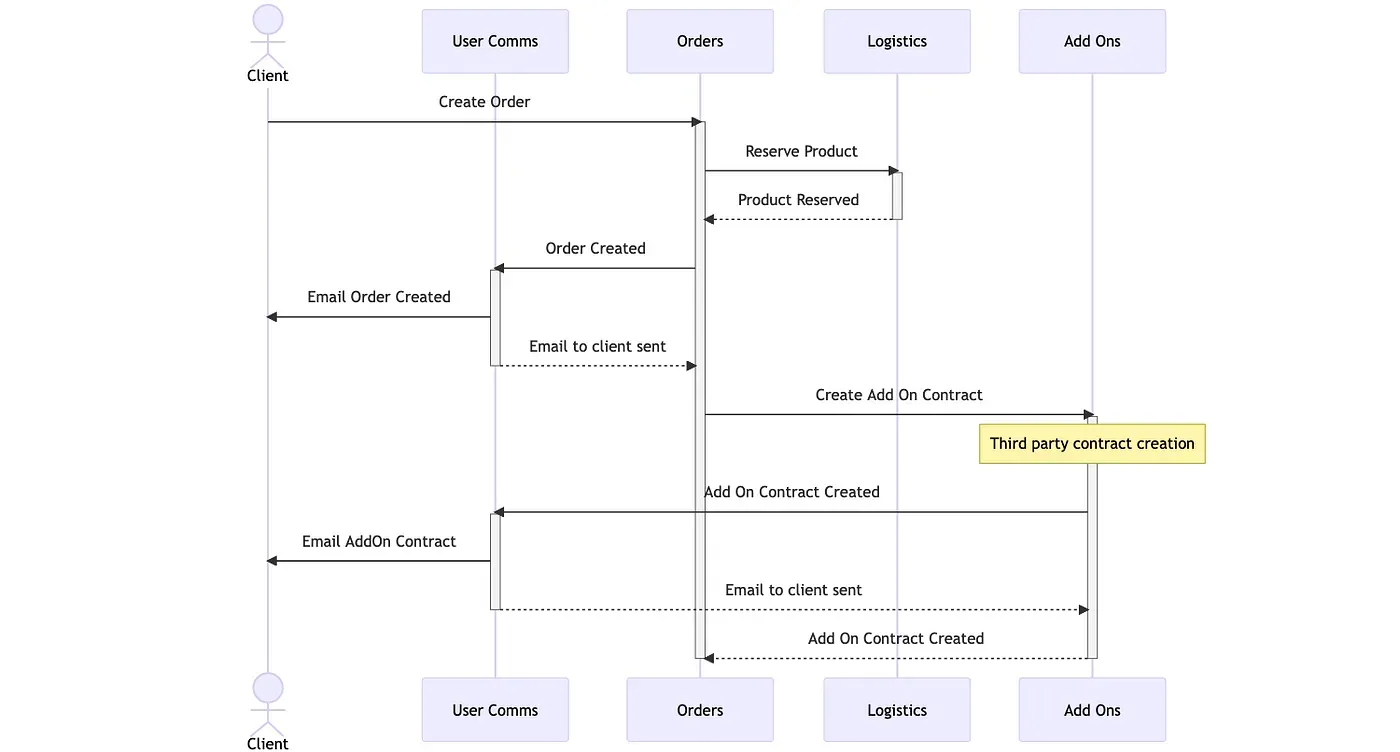
The image above shows an example of a synchronous architecture for when an order is created. We can see that the Orders team takes the task of informing every other team about this information. This causes a big delay and workload in a single team. Now let’s take a look at the same example but using an event-driven architecture.
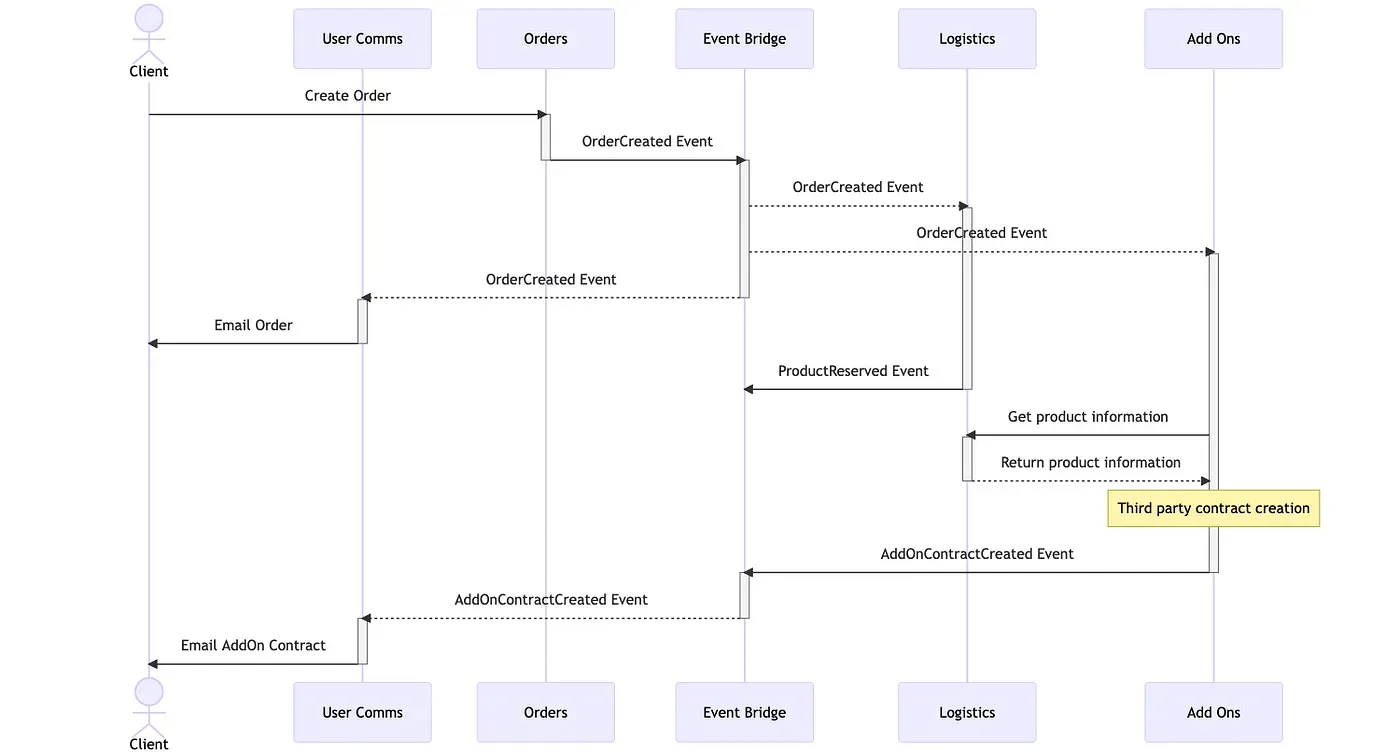
As you can see in the image above the asynchronous example allows multiple teams to do their work independently of other teams’ work. The Orders team is also not forced to wait for them to finish and doesn’t need to worry about who they need to contact, simplifying a lot their workload and business logic.
Problems faced
Of course, no architecture is perfect, and one of the main issues we had while working with event-driven architecture was the lack or poor implementation of event versioning and dealing with unexpected changes that were not properly communicated or well thought through. When changing an event it is important to ensure those changes do not break existing consumers of the event. This can be achieved by maintaining backward compatibility and providing appropriate migration paths for existing consumers. If a given event has to change drastically potentially causing consumers to break when using it, it should be versioned, by either including a version number on the event payload or by creating a new event type altogether.
Another big problem was understanding exactly what kind of events specific teams needed to listen to. For example, for a long time in one of our teams, we had some issues with some third-party contracts that were not automatically cancelled when an order was cancelled or returned for some reason. This was caused by the failure of listening to specific events related to the order cancellation and went undiscovered for some time before it was detected and fixed.
To help mitigate this issue, we had a company-wide repository that held information on all events that all teams were emitting, as well as who was consuming those events. All these events were listed with examples of payloads, so everyone could be aware of not only the events that were being emitted but also what data they carried with them. Each team would list themselves as consumers of events so, in case of changes, they would be informed. We also had RFCs for changes that would be critical for a lot of other teams as well as planned sunsets for events that were going to be deprecated, giving teams time to start using the new ones.
These solutions are not perfect by themselves, after all, people being people will forget to update this kind of data. One way to potentially fix this would be to set up alerts to be triggered whenever an event that is not properly documented in a catalogue is fired, notifying a specific team that would then be responsible for informing the producer of the event that they should update the event data in the catalogue.
Fat vs thin events
Fat or thin events refer to the amount of data that is contained in an event. Fat refers to events that are usually self-sufficient and contain a large amount of data, while thin events contain minimal data, which means that listeners will most likely require to contact other teams for the necessary extra details.
Initially, most, if not all, events in the company would be fat events, as the teams were not building all the endpoints to get the necessary information available on a thin event structure. This allowed for the quick delivery of new features. However, this can lead to some issues as we enumerate below:
- Performance
Fat events can have a negative impact on performance, as they increase the amount of data that needs to be transmitted and processed, potentially leading to delays and slowing down the entire system. - Security
This was only minor in our scenario, but it was still an issue, as teams ended up being able to access data that was out of their remit, opening the way for potential security breaches. - Versioning
Versioning would also be much more challenging as the data structures would constantly be changing in such a fast-growing business. As time went by, these changes kept getting harder and harder to manage without introducing breaking changes.
As we grew, our fat events became harder and harder to manage and we eventually started moving towards thin events. So over time, we replaced our initial catalogue of events with new versions that would send only the bare minimum data, including identifiers that teams could use to fetch additional information if needed. This made the events much easier to manage, and security was less of an issue as the access could now be controlled when the teams requested additional data to the respective systems that owned that data.
As an example, in the OrderCreated event we no longer send all the product details as most consumers won’t require them, so we simply reduce that to an order identifier and the total price. When consuming this event, the add-ons team would request additional information regarding the order items from the logistics team, enabling them to create contracts with third-party systems like insurance companies.
The biggest advantage of this is that we can easily control who has access to which information, which is something critical for clients’ PII (Personal Identifying Information) and we reduce the amount of business logic transferred on the event payloads. This way, most changes to the data structure would not require a new version, after all, we can easily add more information to the event without breaking anything.
But thin events mean that teams are required to contact other teams for relevant specific information, which is not always possible. As such, not all events were thin events and we’re currently using a mixture of both, depending on the results of discussions among the teams involved.
Final thoughts
In conclusion, event-driven architecture is a powerful approach to building distributed systems, but it requires careful planning, design, and implementation to be successful. By understanding the challenges and using the right tools and strategies, you can ensure that your architecture is highly scalable, resilient, and responsive, and serves as a tool to help your organization scale faster.
We hope this article shed some light on some of the things to keep in mind when implementing this type of architecture on a hyper-scaling company, and that it can aid you in your future developments.
Thank you for reading.