Unblocking Feature Flags for faster teams


When working on a fast-growing and fast-paced company with a strong online presence there is usually lots of experimentation going on at any given time. To keep the pace of development and allow for several daily deployments to production, engineering teams need something to control what the users can see and when.
In our quest to assist teams in increasing their performance, we have various mechanisms at our disposal, and one powerful way, in particular, is feature flagging. Feature flags are a powerful approach that can significantly impact Lead Time For Change as it allows much better control and unlocks a higher level of collaboration over the full Software Delivery Lifecycle. But, while feature flags provide significant flexibility, managing multiple experiments and features concurrently can be challenging.
We will delve into an example implementation that can aid others in leveraging and overcoming a few challenges of feature management tools. It is inspired by a use case we faced with a customer, who had low response time requirements, and the challenges of implementing feature flags were hindering them.
By embracing this approach, teams can benefit from centralized configuration and cached storage, ultimately streamlining their feature management processes, optimizing their outcomes, and improving their performance.
Feature Management Primer
Tools
There are many tools to manage how to release features that help make product decisions based on experimentation, a few examples are:
Advantages
- Enables fast flow: It enables trunk-based development
- Control: Full control over the features that users can see
- Toggle vs deployment: No deployment is needed to toggle features on and off
- Targetted: Define the target audience of specific features (e.g. enable a feature for 50% of users or a specific market).
Challenges
Even though feature management tools are great, they come with a few challenges that teams need to mitigate
- Extra HTTP requests: Every time a user accesses a page we need to do an extra request to Split to get the feature flags
- Code duplication: Each team will likely have its own implementation to fetch the feature flags
- No entry point: There is no single entry point to evaluate the feature flags and experiments dynamically if needed
Efficient usage of feature flags
Finally, let's delve into a solution that has the challenges mentioned in mind and keep the integration with the feature management tool efficient and flexible.
The diagram below describes the overall system design using Split as the feature management tool, Cloudflare Worker as an edge server, and AWS API Gateway as the origin server.
Our goal was to minimize the HTTP requests from the user to only one. For that, we centralized the logic of collecting and aggregating all information needed in a Cloudflare Worker, that sits between the user and all other backends (Split + API gateway) in a similar approach to the BFF's (Backend For Frontends) pattern.
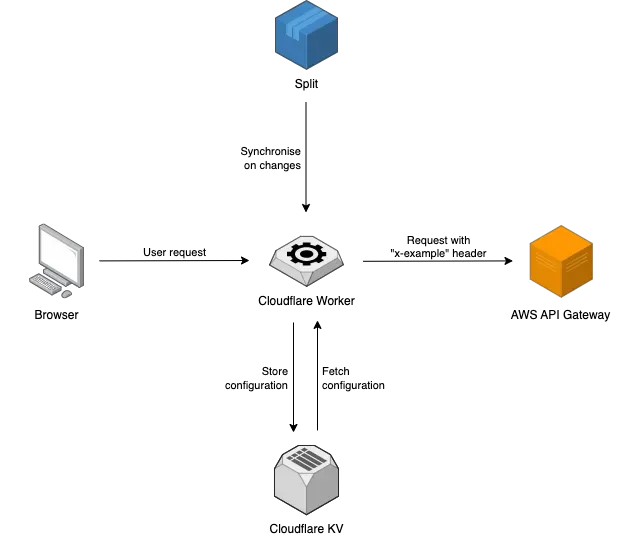
1. Storing feature configuration at the edge
Split is the source of truth of the features configuration and we need to keep it in sync with the Cloudflare KV. To fulfill his purpose, we need to ensure that it holds the latest configuration. The solution is simply to use Split webhooks to synchronize the configuration between Split and Cloudflare KV.
This way, every time the team changes the feature configurations in Split we ensure that we have the latest configuration at the Edge.
2. Communication between edge and origin servers
After having the Split configuration synchronized, our Cloudflare Worker is able to fetch the stored configuration from the Workers KV and forward the request to the origin server with this information in an HTTP header. We should however take into account that the HTTP request has size limitations.
The Amazon API Gateway has a hard size limit of 10240 bytes for the headers, so it’s better to have a threshold mechanism for the number of feature flags. This mechanism can also integrate with Slack or another similar tool to alert your team when you’re approaching the size limit.
As an improvement to reduce the “x-example” header size, we can try to send only the feature flags we need based on the current request.
Benefits
- Centralized configuration: There is an entry point where we can manipulate data before exposing it to the applications.
- Cloudflare Workers KV as storage: The feature flags are stored in a global and low-latency key-value data store with a cache system.
Caveats
- HTTP request size: Usually origin servers have limits for the HTTP request, in our case the Amazon API Gateway has a hard size limit of 10240 bytes for the HTTP headers size.
- Page cache on the Cloudflare Worker: The percentage of cache hits can be small since the “x-example” header isn’t always the same because of the possible values from the feature flags.
For our customer use case, the benefits overweighted the caveats. We ensured every team had a single entry point, minimized the requests and flicker effect by following the BFF pattern and the Cache-Hit-Ratio was still very acceptable.
A few alternatives
There are different approaches for feature flags, depending on what you need to optimize for. For smaller teams maybe you don’t need the flexibility of a platform like Split or if they are not updated frequently you can play differently with caches.
- Cache the request locally and play with the sync times you need for your use case
- Define feature flags as environment variables directly in the code when they don't change frequently (this means, you will need to deploy every time you want to change the configuration)
- Use the SSM to store the feature flags and then turn them on and off through the AWS console
Conclusion
At xgeeks, our mission is to empower teams and transform them into high-performing organizations.
By empowering our customer to integrate feature flags into their Software Development Lifecycle, we achieved a remarkable enhancement in the collaboration between Product Managers and Software Engineers. This implementation provided them with greater control over the features, leading to streamlined communication and improved coordination.
Moreover, this breakthrough prompted a transformation in the branching strategy, transitioning to trunk-based development. This strategic shift had a profound impact on the velocity of software releases to production. The adoption of feature flags and trunk-based development resulted in shorter feedback loop cycles with end users, enabling rapid iteration and refinement!