Enterprise information retrieval with Azure AI Search

Generative AI is already having a massive impact across all industries, and at xgeeks we've been actively learning, testing and developing real solutions within this new landscape.
Most recently, we developed an AI-powered pilot for an enterprise client all within the Azure ecosystem.
In this article we'll dive into the solution we built for this first iteration of a chat application that allows users to talk with technical manuals and data sheets.
This article will focus on the following topics:
- The problem we need to solve
- The Azure AI solutions we used
- Our approach
- Future enhancements
Challenge
This particular company has a support team that handles calls and emails from customers asking questions about their products. To be able to answer, they need to find the right document for the product, as each model can have documentation in different languages, and some with operation instructions and others that are data sheets. After they find the right source, they need to find the information that the customer needs, that can be present in text, image or table formats.
The challenge here is to streamline and automate as much as possible all these steps, to reduce the feedback loop between the support team and the customer.
Our idea was to build an AI-powered solution to increase the responsiveness of their support team when looking for information in operating instructions manuals and product data sheets.
The initial iteration would consist in a chat application where the support team could ask questions about any product they have to quickly find the information they needed.
The app needs to be able to:
- Understand what product model the user is asking about.
- Get the corresponding files for that model in German or English, depending on what language the question is asked.
- Answer the question.
- Render the pdf file section from where the information came from.
Our Approach
To build our AI-powered chat, we need:
- A place to store documents, so we can then show where did we get the information to generate our answer.
- A search engine, able to convert our text into vectors, able to save extra metadata with page numbers, product name, type of file and language, able to filter for these parameters and retrieve relevant context.
- A language model, that can receive context and provide correct answers, without hallucinating.
- This solution would need to work within the client's Azure ecosystem.
Storage
Azure Blob Storage is a storage solution for the cloud that let us save a large amount of unstructured data. In this specific case, we didn't need a regular database, we just needed a place to store and load our documents (pdf files). These documents were initially being saved in the client's SharePoint, but we needed a place where the search engine and our frontend could easily access it, so this was the best option for that purpose.
Search Engine
Azure AI Search is an information retrieval platform, powered by AI. It has an indexing engine, so it's capable of transforming our data into vectors. After that, it stores the data in vectors and plain text and also allows to add some metadata into an index. It was our choice because it allows us to save our texts, embeddings and metadata all in the same place, while having great search capabilities, providing fast and accurate results, a good match for our requirements.
LLM
The Azure OpenAI Service provides us access to OpenAI's language models. We can access all models available from within Azure. This service is more suitable for enterprise applications, offering superior security capabilities, LLM data privacy, while also supporting VNETs and private endpoints, all under Azure Cognitive Services SLAs.
Solution
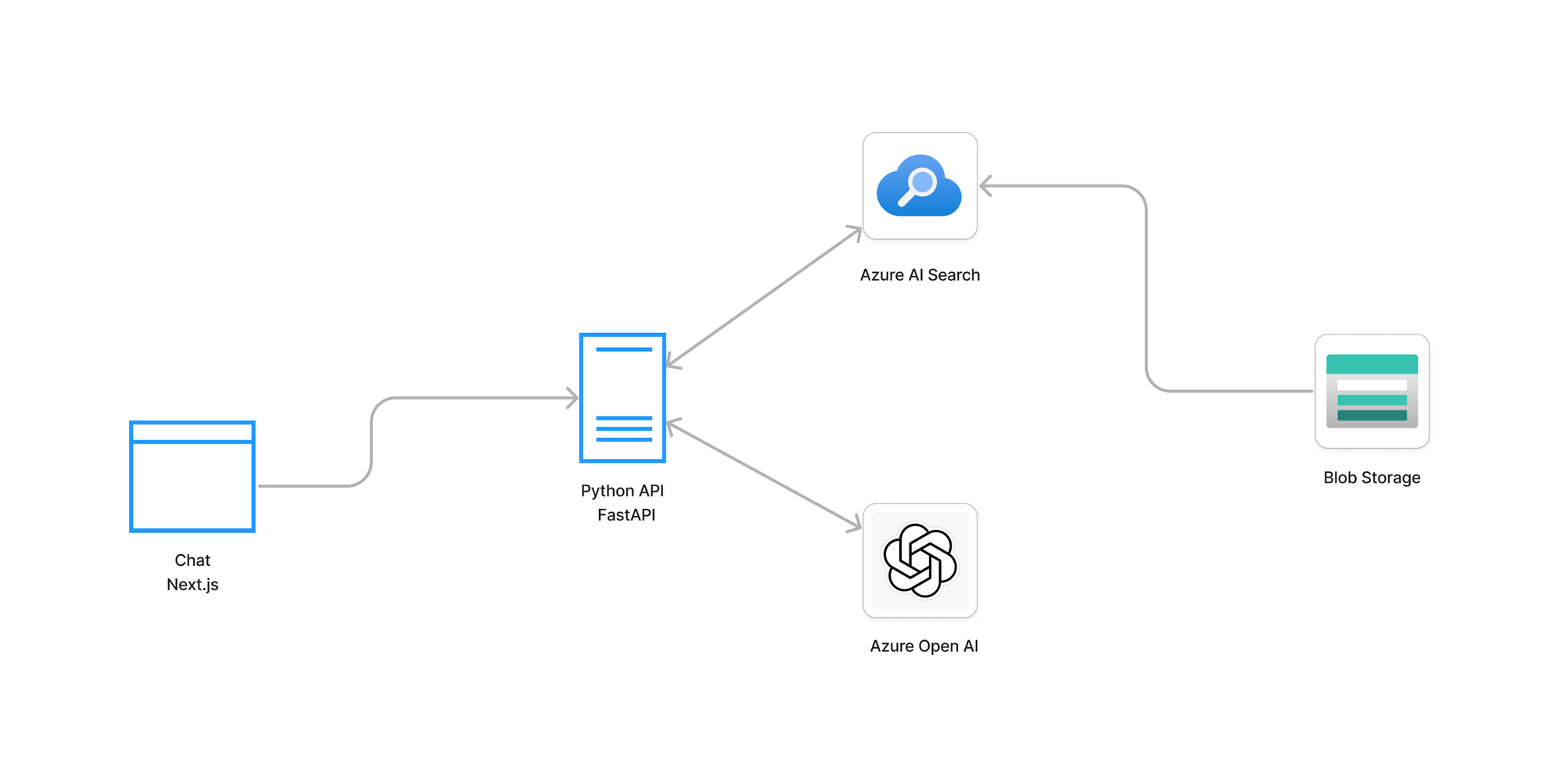
Storing Data
To have our data ready to be queried, we first had to upload all of the files in the blob storage service. We decided to upload one file per page, so in the frontend we could show the page that was used to answer the user question.
Indexing Data
After uploading data, we relied on Azure AI Search to create the embeddings using text-embedding-ada-002 and store them in an index. We did this process of storing in the index by page as we did when storing files. To have additional information stored, so we could then filter our documents, we didn't only save the content of the files, but we also saved the filename (title), the number of the page (page) and also, the model of each product, language and type of the file based on the filename (category).
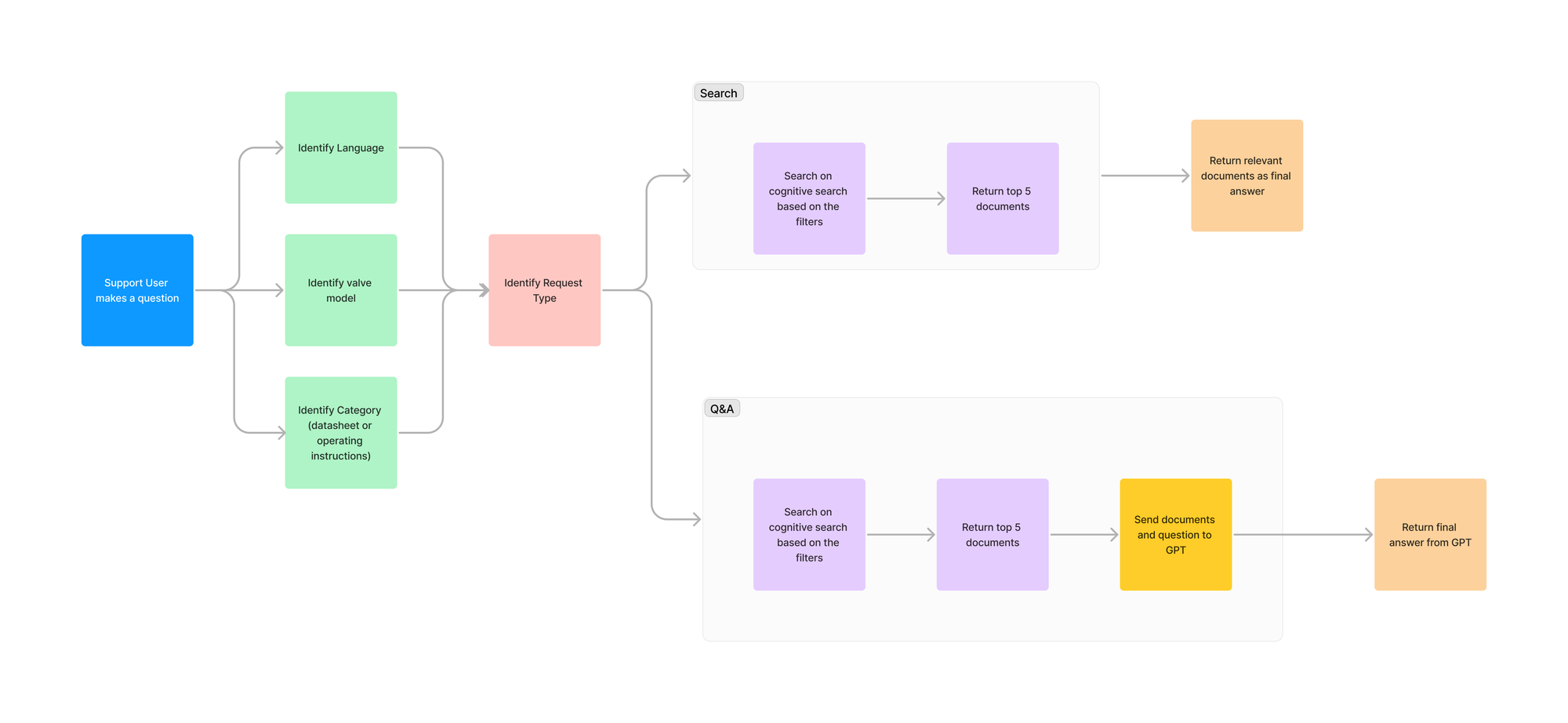
Analysing questions
Everything starts with the user's question. This question triggers a request to our API. The first thing we do is identifying the product model, the language, the type of request and the type of document. For each of these parameters, we do a call to the LLM to identify them and then use it to filter the documents.
The type of request can be "search" if the user asks to retrieve a document (e.g. "Can you send me the document for product model X"?) or it can be "question and answer" if the user asks something specific about a product (e.g. "Can you provide me the temperature ranges for model Y"?).
Depending on the type of request, the process can continue one of two ways:
- If the type of the request was "search", we used the information that we got from the question to filter our search with AI Search and get the required document. In this search we used hybrid search to return us the top 5 results, in this case the top 5 pages, that we use to fetch the filenames of the documents we need to send back to the user.
- If the type of the request was "question and answer", we searched using semantic hybrid search with score and rerank, to return us the top 5 pages related to the question, also filtered by the identified parameters. Then, we would send to gpt-4-turbo model as context, to get a proper answer. After that, we would send the answer back to the user.
Future Enhancements
With this first iteration, we already provided a solution that improves considerably the search and response time of the support team. Nonetheless, we can already identify some areas for improvement for a subsequent iteration:
- To optimize performance we could use caching, in a way that, when a user asks a question that someone or even himself already made, instead of doing another call to the LLM, we would just use the cache to get the answer, possibly also storing them as embeddings in a vector store.
- We can also try to optimise cost and speed by mixing different models for specific tasks where cheaper and faster models are good enough for the task.
- Furthermore, we could train and fine-tune an LLM model using the client's data which in turn will save us on token consumption, request latency and output quality.
Final thoughts
Azure AI services, specially Azure AI Search and OpenAI, are an excellent entry point for enterprises that want to add AI capabilities to their applications and data. Many enterprises already trust Azure with that data, enabling us to build a robust proof of concept all within this ecosystem in a short amount of time.
At xgeeks we are already enabling companies to take advantage of the AI revolution, so stay tuned for more insights and breakthroughs in the near future!
Meanwhile, here's an article that might interest you:
 André Gonçalves
André Gonçalves