Optimizing an Airflow DAG development lifecycle


xgeeks mission is to transform teams into high-performing organizations. In one of our projects accelerating an organization's performance, we have taken on the responsibility of managing the data infrastructure for a leading automaker to improve its development speed and quality. This article shows you how we solved one of the pain points we identified, leveraging the elasticity of the cloud, a DevOps mindset, and cloud-native capabilities.
The scope and primary objective were to fetch and process data used to populate vehicle information data to be consumed by different APIs. This involved a data pipeline process, where the data had to be extracted, transformed, validated, and enriched based on a set of predefined rules.
Airflow was the workflow management tool, which served as the central component of the data pipeline. In Airflow, each workflow is represented as a Directed Acyclic Graph (DAG) written in Python. Although the technical details of Airflow are beyond the scope of this article, it suffices to say that it plays a crucial role in ensuring the data quality and smooth operation of the system. It fetches data, processes it, and ensures that other components receive the data in the required format, being a key component of the data infrastructure.
We realized there was a challenge in the DAG's development lifecycle and we took it as an opportunity to dramatically increase its speed, quality, and developer experience.
If you're interested in knowing how we improved Lead Time For Change by a factor of 3 while at the same time improving Change Failure Rate, keep reading!
Deep into the challenge
By having a look at the software development lifecycle of the DAG's we identified a big bottleneck.
The team was following a GitFlow approach with feature branching. Each developer created his own feature branch and only after merging and deploying to the E2E test environment, QA Engineers could start the feedback loop with engineers.
Here's a very simple overview:
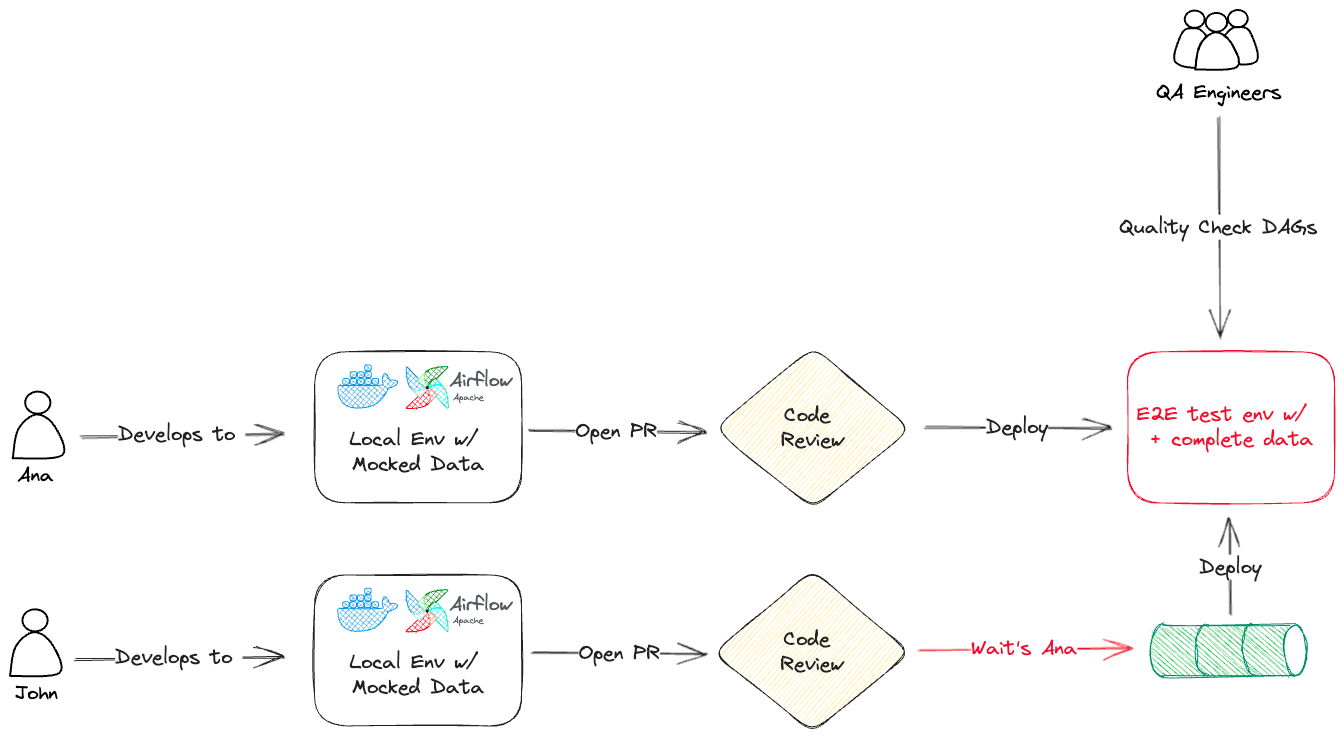
- Ana works on their local development environments and get direct feedback from unit tests and does first validations running DAG's against mocked data
- A pull request is opened by Ana for John to review and if everything is ok, it's deployed to the end 2 end test environment
- QA engineers now can perform quality checks against more complete data on the End 2 End test environment
- John has his work completed, but it can't be deployed / it's risky to deploy to the End 2 End test environment since QA engineers only have one single shared environment
The existing setup had two major issues.
1) It was underoptimized for the available resources
QA engineers could be doing more quality checks but were relying on and were blocked by the worries (described below) that one single shared instance to perform E2E tests create. Needless to say that this was a huge hassle and it was dragging the entire release process.
2) It was affecting the validation quality
When performing any kind of quality check on the DAGs, test data management and ensuring a valid initial state of the environment is critical to ensure the quality of the tests to avoid any false errors and takeaways out of incorrect starting state. A lot of coordination and communication was needed between quality engineers and even developers in order for this to work, making it borderline impossible to manage.
In order to enhance our quality check process, we have recognized the need for isolated environments where QA engineers can run end-to-end (E2E) tests on specific DAGs without affecting the shared testing environment. For example, when testing a DAG that cleans up database data, it is not ideal to perform these tests in a shared environment where other individuals might be relying on the database state for their own tests. Although backups from snapshots are possible, it would be advantageous to have dedicated, reproducible and ephemeral environments with proper test data management for QA testing purposes.
Shifting quality left with APEs
To address this, we have decided to enable QA engineers to start having an impact in the Pull Request stage, or even before! Allowing QA engineers to perform E2E tests as early as possible in the development process. We did this by launching isolated environments for each feature/DAG, allowing the QA team to target specific tests without impacting other ongoing tests. This approach seamlessly integrates E2E tests into our existing GitFlow without the need for any significant changes to the existing processes.
We called these environments Airflow Preview Environments (APE).
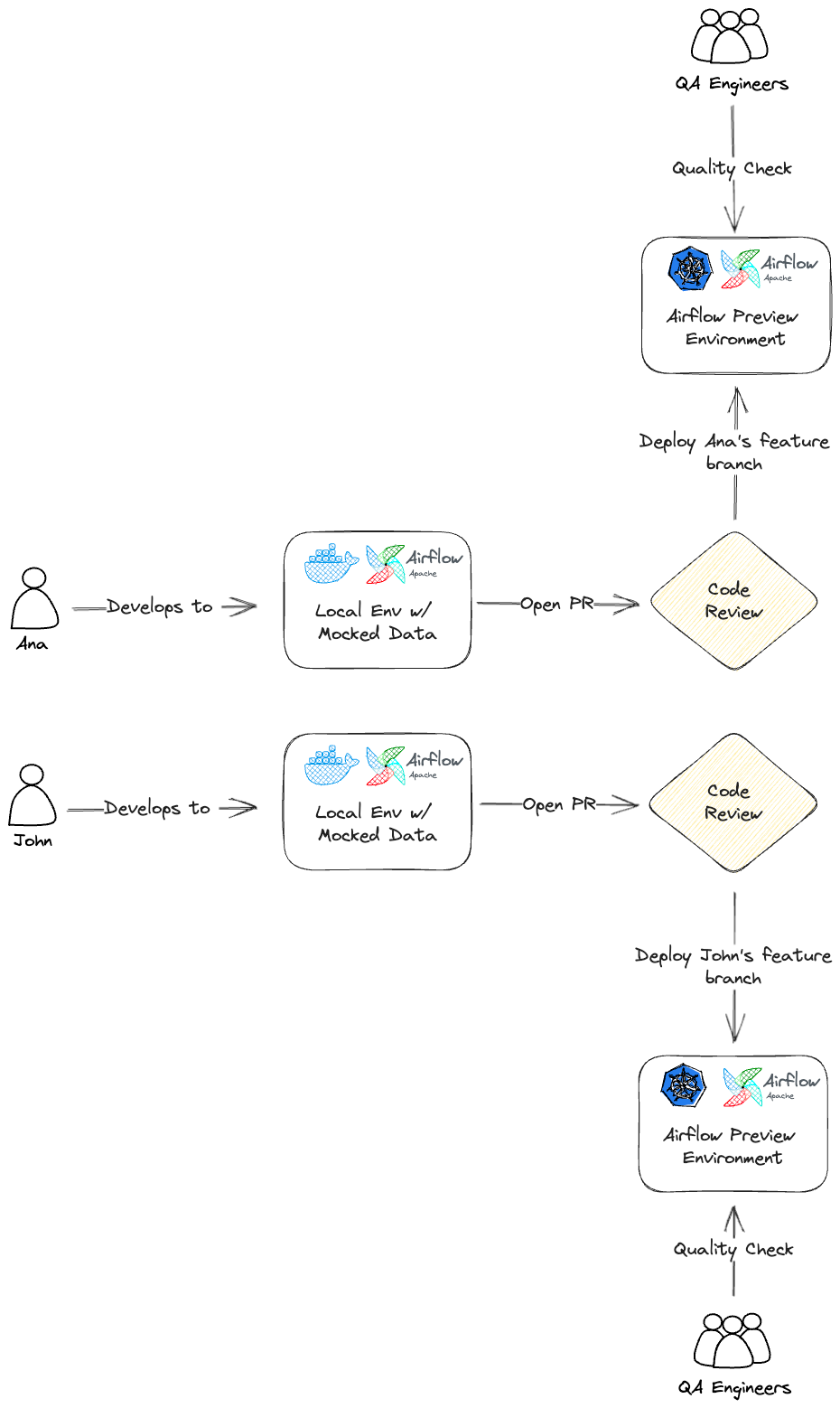
Airflow Preview Environments implementation
In a nutshell, an Airflow Preview Environment needed to be:
- Isolated
- Ephemeral
- Reproducible
- Deterministic
- Fully automated
- Fully packed with everything we need for E2E/integration testing
Our goal was to spin up a minimal operational Airflow environment isolated from everything else, to be used on demand and then deleted when the DAG has been through the QA engineers' feedback loop.
How did we integrate them into the development lifecycle?
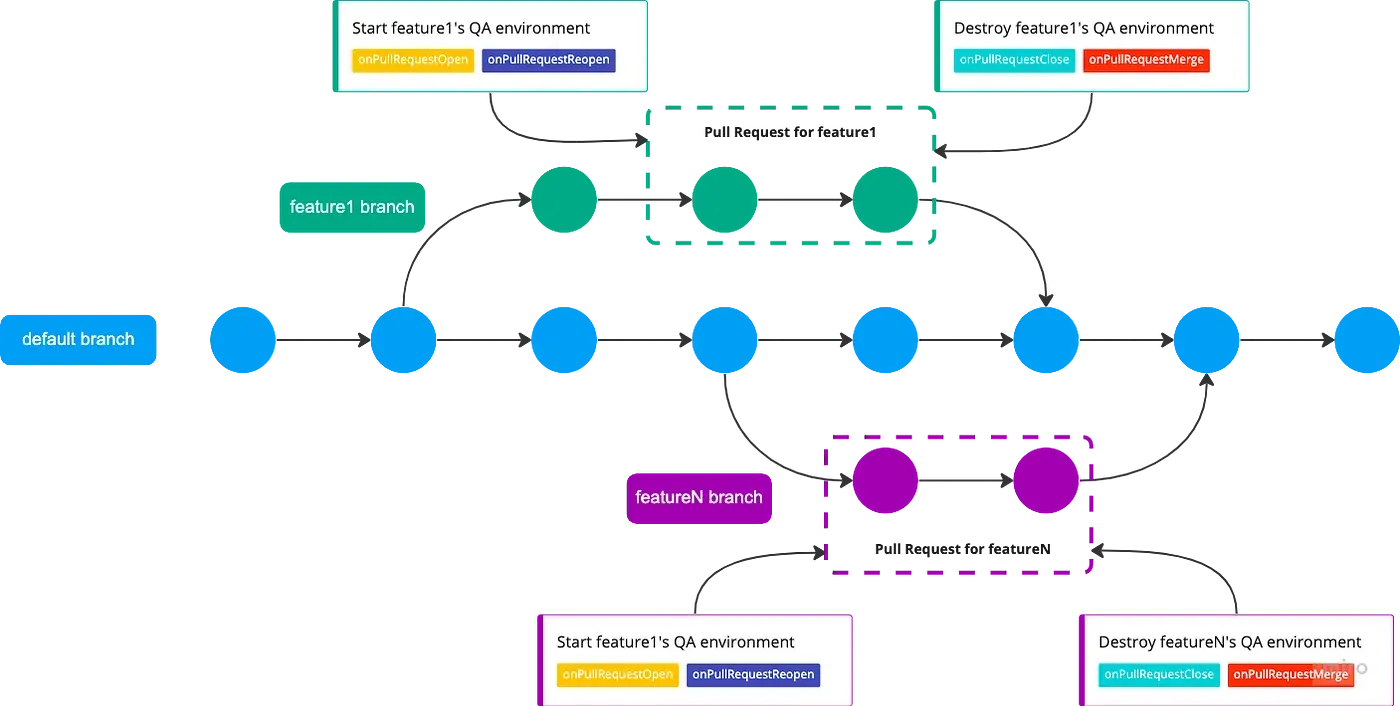
- A new branch (feature1) is opened from our main branch (default)
- A team member works on his feature1 branch
- It then opens a Pull Request (PR) to our main branch
- The Pull Request automatically triggers the spin-up of one dedicated APE
- A new environment is automatically created and the developers can easily share the spun-up APE with the QA Engineer
- Once the PR is closed, the APE is automatically destroyed
Tools and technologies used?
Here’s an overview of the infrastructure stack and technologies, and how we used them to achieve our goal
- Kubernetes — as our orchestration tool. This was the orchestration tool already used for all other environments (dev, staging, production) so it made sense to use it to also deploy our APE.
- Helm — For managing Kubernetes-based apps
- GitHub Actions — All our CI/CD pipelines ran on top of GitHub Actions
- AWS Secrets Manager — To securely manage the secrets needed
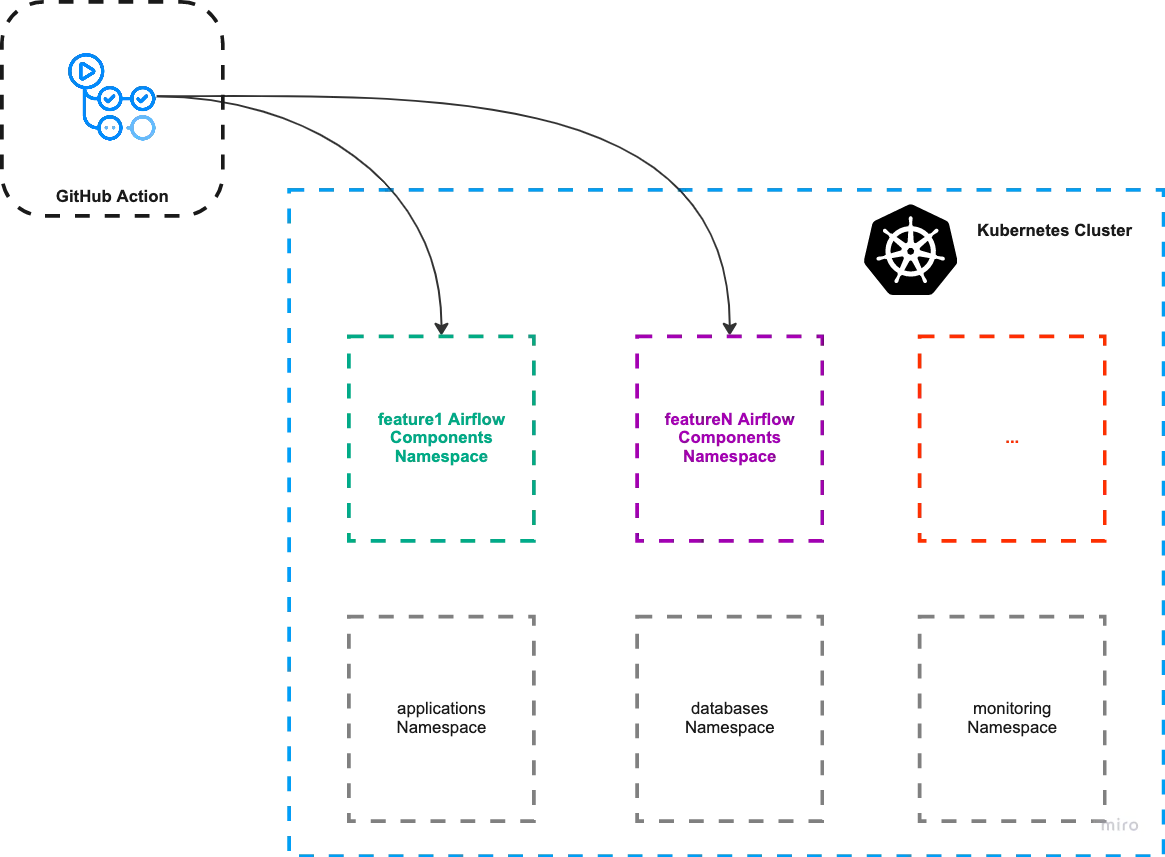
Let’s now take a look at the GitHub Action responsible for the lifecycle of an Airflow Preview Environment.
1. Defining the triggers to launch the APE
First, we defined the triggers. We want it to run for every PR that is opened or re-opened to our default branch as we see in the above image.
on:
pull_request:
types: [opened, reopened]
branches:
- defaultTo ensure proper namespace naming for launching isolated environments, we follow a specific process. We start with a predefined string, "airflow-preview," and append the name of the origin branch of the Pull Request (PR). However, Kubernetes imposes a limitation of 63 characters for namespace names. In some cases, the concatenated name exceeds this limit.
To address this, we have implemented a job that handles the namespace naming. This job intelligently truncates the name to a length that still uniquely identifies it within the entire cluster. The output of this job provides the modified namespace name, which is then used by the deploy job.
By implementing this solution, we guarantee that our namespace names adhere to the character limit while still maintaining uniqueness within the cluster.
jobs:
curate-name:
runs-on: 'self-hosted'
steps:
- name: Curate environment name
id: curate_name
run: |
final_env_name=$(echo airflow-preview-${{ github.event.pull_request.head.ref }} | cut -d "-" -f1-4)
echo "::set-output name=env_final_name::$final_env_name"
outputs:
env_curated_name: ${{ steps.curate_name.outputs.env_final_name }}2. Deploying the components and making the environment accessible
The next step is to deploy the components. Since we have these specific charts hosted in the same repository we first checkout the code to then deploy the secrets chart followed by the Airflow chart. We do this using by using the bitovi/github-actions-deploy-eks-helm action. You can check the reference for this action here.
deployment:
runs-on: 'self-hosted'
needs: [curate-name]
environment:
name: ${{ github.event.pull_request.head.ref }}
url: https://${{ needs.curate-name.outputs.env_curated_name }}.your-domain.com
steps:
- uses: actions/checkout@v3
- name: Deploy Airflow Secrets Helm Chart
uses: bitovi/github-actions-deploy-eks-helm@v1.1.0
with:
aws-access-key-id: ${{ secrets.AWS_ACCESS_KEY_ID }}
aws-secret-access-key: ${{ secrets.AWS_SECRET_ACCESS_KEY }}
aws-region: ${{ secrets.AWS_REGION }}
cluster-name: ${{ secrets.CLUSTER_NAME }}
config-files: helm/airflow-secrets/values.yaml
chart-path: ./helm/airflow-secrets
namespace: ${{ needs.curate-name.outputs.env_curated_name }}
name: airflow-secrets
version: 1.0.0
values: aws.access_key_id=${{ secrets.AWS_ACCESS_KEY_ID }},aws.secret_access_key=${{ secrets.AWS_SECRET_ACCESS_KEY }},git.ssh_key=${{ secrets.AIRFLOW_GIT_SSH_KEY }}
timeout: 60s
atomic: true
- name: Deploy Airflow Helm Chart
uses: bitovi/github-actions-deploy-eks-helm@v1.1.0
with:
aws-access-key-id: ${{ secrets.AWS_ACCESS_KEY_ID }}
aws-secret-access-key: ${{ secrets.AWS_SECRET_ACCESS_KEY }}
aws-region: ${{ secrets.AWS_REGION }}
cluster-name: ${{ secrets.CLUSTER_NAME }}
config-files: helm/airflow_values_preview.yaml
chart-path: apache-airflow/airflow
namespace: ${{ needs.curate-name.outputs.env_curated_name }}
name: airflow2
chart-repository: https://airflow.apache.org/
version: 1.6.0
values: ingress.web.hosts={${{ needs.curate-name.outputs.env_curated_name }}.your-domain.com},dags.gitSync.branch=${{ github.event.pull_request.head.ref }}
timeout: 360s
atomic: trueIn this job, we also create a GitHub environment so that the developers have a direct link to the APE in the GitHub UI.
3. Ensuring security with proper secrets management
Airflow allows you to store connections (to an AWS S3 Bucket, for example) and variables. You can do this manually or load them via JSON file for example. By using the Airflow Secrets Manager backend we can have Airflow consuming these values directly from AWS without any “trails” of them in the cluster. This is where the AWS Secrets Manager comes in handy.
If you use the AWS Secrets manager backend don’t forget to pass the AWS access secrets like we are doing on the Deploy Airflow Secrets job.
backend_kwargs = {"connections_prefix": "airflow/connections", "variables_prefix": "airflow/variables", "profile_name": "default"}With this new environment deployed the QA engineer can safely run their quality tests for as long as they want without being concerned about impacting the work of another peer.
4. Cleaning up
Once the quality check is approved by the QA Engineer and the code is merged, the pull request is closed automatically triggering the clean-up flow of the Airflow Preview Environment.
Now we need to clean up the Kubernetes namespace we created and the GitHub environment that we don’t need anymore.
- name: Deleting namespace
uses: ianbelcher/eks-kubectl-action@master
with:
aws_access_key_id: ${{ secrets.AWS_ACCESS_KEY_ID }}
aws_secret_access_key: ${{ secrets.AWS_SECRET_ACCESS_KEY }}
aws_region: ${{ secrets.AWS_REGION }}
cluster_name: ${{ secrets.CLUSTER_NAME }}
args: delete ns ${{ needs.curate-name.outputs.env_curated_name }}
- name: Deleting environment
run: |
curl -X DELETE -H "Accept: application/vnd.github+json" -H "Authorization: Bearer ${{ secrets.AUTH_TOKEN }}" [your-repo-url]/api/v3/repos/your-org/your-repo/environments/${{ github.event.pull_request.head.ref }}To delete the namespace we use the ianbelcher/eks-kubectl-action action and, for the environment deletion, we perform a simple curl DELETE request to the GitHub API where we provide the name of the environment to erase.
Final thoughts
At xgeeks, our mission is to empower teams and transform them into high-performing organizations. Through our collaborations with prominent companies and teams, such as the one described in this article, we have reaffirmed our belief that success lies in paying attention to the finer details. By implementing a seemingly simple adjustment, leveraging the elasticity of the cloud, and adopting cloud-native practices, we enabled our customers to achieve substantial improvements in various crucial areas.
Notably, this modification had a significant impact on the speed, quality, and developer experience of the team involved in the project. By reducing the feedback loop and minimizing the lead time for changes, our client experienced enhanced agility, which in turn led to improved business outcomes.
We understand that even the smallest tweaks can bring about substantial benefits, and we strive to help organizations unlock their full potential by focusing on these critical elements. Through our efforts, we aim to support teams in achieving remarkable efficiency, productivity, and ultimately, remarkable success.