Our Approach to Microservices



Often, we hear the importance of splitting software into smaller components when speaking about microservices. Interestingly, these principles date back to the 70s and refer to the good practices we should adopt in code design. A perfect example is the Unix philosophy, already proven from theory to the real world, with its implementation as the ultimate and time-tested proof. Let’s review some of the main principles followed, summarized by Peter H. Salus:
Write programs that do one thing and do it well.
Write programs to work together.
Write programs to handle text streams, because that is a universal interface.
In the last years, the growth of cloud-native tools boosted microservices adoption, bringing these principles back to the spotlights. Automation, virtualization, and containerization stand as pillars of cloud-native that enable teams to apply different development practices with infrastructure in mind. As a consequence, it became a trend and a default to implement distributed systems.
At xgeeks we've been supporting many of our customers navigating this trend in their journey to become better-performing engineering teams and we're happy to share some lessons.
A trend that became a problem
We believe everything in software engineering is a tradeoff. There’s no right or wrong and while distributed systems and microservices have many advantages they also bring downsides and challenges if not applied correctly, or even worse, if they not are not serving any real need.
We often see teams beginning a new project with unclear scope, trying to implement microservices from the get-go. Something we discourage since it leads to unnecessary costs and maintenance horror stories! Here are the top 5 challenges we see:
- Communication complexity: the system becomes more complex as it comprises multiple services that communicate with each other over a network. Instead of simple method calls, your team now needs to think about different and more complex communication models over the wire
- Data consistency: each service may have its way to read and write data, making it difficult to manage data consistency and integrity across the system. Eventual consistency is now a needed skill in the team
- Operational overhead: As the number of services grows, the operational overhead increases, including distributed monitoring, logging, and debugging. Teams need to be equipped with the necessary skills and tools to manage the system effectively.
- Testing complexity: Testing a microservices architecture is more complex than testing a monolithic architecture. Each service needs to be tested in isolation and as part of the larger system, making testing more time-consuming and challenging.
- Cost fallacy: While microservices can help organizations scale and be more agile, implementing a microservices architecture can go both ways. Unfortunately, many times the wrong way. It requires significant investment in terms of infrastructure, tools, and personnel.
Overall, while microservices offer several benefits, we believe the team must be strong in code and system design to leverage them. It should also allow the code design to develop and reach a maturity level where the code boundaries and specific service infrastructure needs become clear. Otherwise, the most likely scenario is for the team to end up with a distributed monolith that creates more problems than it solves.
Introducing the modular monolith
A modular monolith is essentially a monolith that’s designed with modularity in mind. This means that different components of the system are organized into separate, cohesive modules that can be easily modified without affecting other parts of the system. Remember the Unix principles?
In many ways, a modular monolith can solve most of the challenges that microservices try to address, without the distributed complexity.
The real challenge in code and system design is achieving modularity and there are different ways to achieve it, i.e: Domain-Driven-Design. How to achieve it is worth a whole new post (we’re on it…)! The key takeaway we would like to give is that this approach can derisk the development process, and make it easier to maintain and modify the system over time, without relying on the complexity of microservices, let alone, a distributed monolith before it’s really needed.
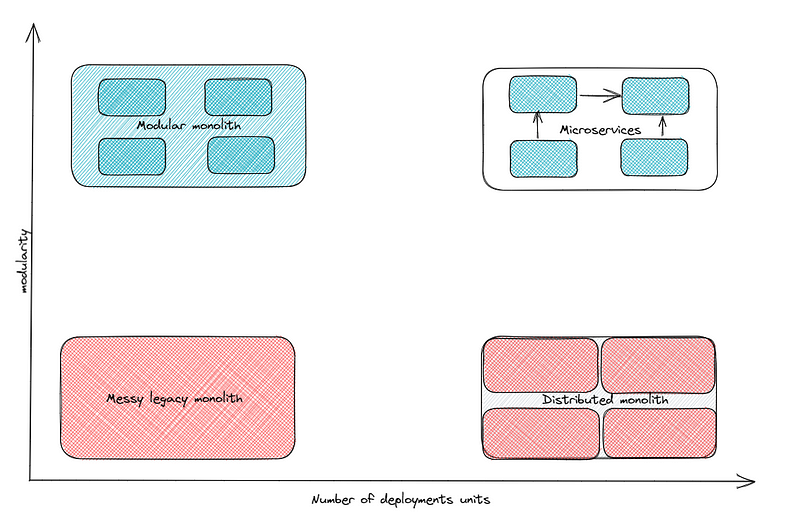
Nevertheless, the wonders of the modular monolith aren’t removing the real value microservices can bring to a team and an organization. Let’s discuss them below.
What if there’s a real need?
There are many known generic reasons for microservices to make sense. From experience working with big teams, we always like to balance the historical context and future needs to decide when to use it.
From our experience, it varies a lot depending if we’re on a greenfield or brownfield project. But, In the end, it always boils down to when there’s a real need for:
- Different DORA and QoS targets per service & team
- Split ownership and service governance
- Tech stack modernization
If any of the above is becoming a pressing need and there’s no other way around it, microservices (technical dimension) with the right team topology (organization and governance dimension) are our go-to tools to solve them!
Here’s a simple playbook of how we look at it for greenfield projects!
1. Achieve modularity with code design
Modularity is what we’re looking for! By being on the right track in regards to code design, and consequently having clear domain boundaries popping up while code evolves, with needed communication models and resilience needs it becomes increasingly easier to identify what should or not become a microservice without premature complexity
2. Figure out the right team topology for governance reasons
In parallel, if any of the needs start pressuring we analyze the right team and governance needed to start splitting the previously identified domains and boundaries popping up on step 1.
3. Create independent release pipelines
With 1. and 2. sorted out, it’s time to understand the technical changes needed to achieve independence. There are common fronts needed around creating independent release pipelines, distributed observability, and different communication models (say goodbye to synchronous HTTP requests)
Following this playbook, we ensure we keep things as simple as possible while leaving the doors open for further scale!
The story and starting points are a bit different for brownfield projects… that’s the reason why we put in the hoven a separate and dedicated article addressing this scenario.
Final thoughts
With this article, we want to raise awareness and our experience that microservices are a double-edged sword that organizations and teams should play with carefully.
Many people in the industry are making it a standard without emphasizing the complexities and costs they bring. Nevertheless, they also create immense and impactful benefits that can change the direction of a whole organization when done right. This is where we can help!
xgeeks is a valuable technology partner that can support defining your technology strategy and implementation and we help organizations weigh the costs, complexities, and real opportunities associated with microservices before deciding whether and how to adopt them