Solving performance issues for customer facing applications at scale



When creating a platform designed to handle large amounts of data with quickly changing schemas and structures, the utilization of NoSQL databases is crucial for the necessary adaptability.
Each tool has a distinct role, and choosing the most appropriate option customized to your specific circumstances and requirements is vital, given that each tool possesses its own set of advantages and disadvantages.
In situations where there is a high volume of write operations and minimal read activities, opting for a database type that prioritizes write performance and scalability is typically favored. NoSQL databases are commonly deemed more appropriate than conventional relational databases in such contexts.
In this specific situation, a substantial amount of writing is essential given the dynamic characteristics of the data. NoSQL databases address our writing volume challenge, yet they can also present significant challenges when data scales in size and requires fetching and filtering for end-users of the applications. In this particular scenario, Search Engines can serve as invaluable allies.
This article elucidates strategies to address a significant challenge: response times during the execution of extensive filtering, data retrieval, and sorting operations using NoSQL databases.
We will go through:
- Understanding the Challenge
- Why you need to rely on data
- A/B testing with real usage traffic
- Load testing
Understanding the Challenge
Individuals frequently depend on assumptions rather than facts. We, engineers, are designed to address challenges by implementing enduring solutions rather than temporary patches. Therefore, prior to engaging in practical tasks, it is imperative to grasp the underlying concept comprehensively. In this regard, data visualization and factual information play a crucial role.
The recently onboarded project involves a significant ETL process tailored for a prominent corporate client headquartered in Europe, specializing in the automotive industry. The primary objective of this initiative is to extract vehicle data from various sources, perform necessary transformations, and deliver it to upstream systems for online retail purposes while also making it available through API's for other consumers. It is imperative for the team to ensure the continuous availability and functionality of the system, as any disruptions could significantly affect the client sales on the online shops that are operating across multiple markets in the European Union.
This project has encountered significant challenges regarding response times during data retrieval primarily attributed to the continuous growth in data size over time. The dataset has undeniably expanded over time, yet forecasts regarding its future scale remain absent. This absence of information significantly influenced our approach to problem-solving, necessitating consideration of this unpredictable variable.
These response times have shown an increase corresponding to the level of data filtering applied by users, resulting in an average response time of 1 minute and 4 seconds, with a peak of 3 minutes and 56 seconds. The prolonged wait of approximately 4 minutes for users to receive data after adjusting a filter is suboptimal. In reality, the server is likely to time out before the user receives the response. Upon analyzing these metrics, it became apparent that employing more filters would likely result in the outcomes aligning with higher percentiles.
Rely on data, not assumptions
Engineers face significant challenges when relying on assumptions, as our problem-solving approach is grounded in addressing tangible issues based on data-driven decisions and not assumptions.
Our source of truth for the data essential to solving the problem was facilitated by our Application Performance Monitor (APM), which provided us comprehensive metrics such as average response times, latency, maximum values, and percentiles. This tool furnished us with essential insights to pinpoint the root cause of the issue effectively. Additionally, APM platforms typically offer visibility into time-consuming processes, enabling us to swiftly recognize the bottleneck located within our database.
Upon analyzing our database monitoring data, it became evident that vertical scaling, which involves increasing resources, would not resolve the issue. Nevertheless, we implemented a temporary vertical scaling measure to illustrate and document that scaling alone would not address the underlying problem.
The percentiles served as the initial metric utilized for establishing a basis of comparison. Prior to delving further, we pinpointed potential user queries that aligned with the response times corresponding to the percentiles (P50, P75, P90 and P99).
Given the issue arose from the ongoing expansion of data volume, we opted to scale the data during collection by factors of 2 and 5. This initiative aimed to assess the system's performance under increased data loads for the future.
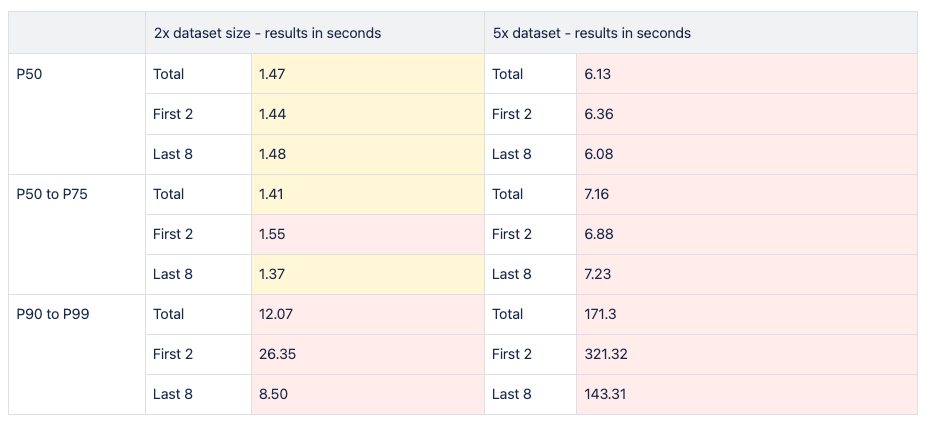
Upon examination of the image provided, it is evident that the dataset's size directly correlates with an increase in response time over time. Due to the data caching behavior of our database engine, a methodology was adopted where the query is executed 10 times, with the initial two iterations isolated for distinct analysis from the subsequent eight iterations.
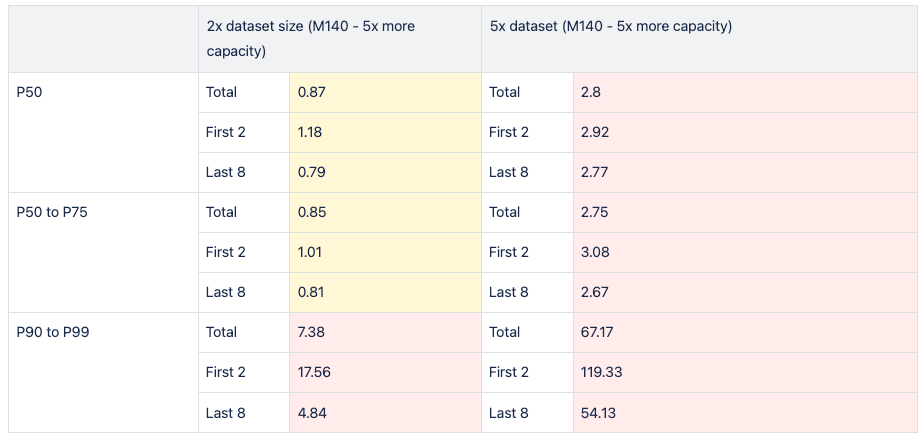
As previously stated, we conducted identical tests in a scaled environment, demonstrating that vertical resource scaling would not provide a lasting solution to our issue.
In the course of this analysis, we diligently optimized our database indexes to their fullest extent. However, we encountered a threshold where sustaining all indexes alongside the numerous applicable data filters became unfeasible.
Given that scaling resources and reviewing indexes did not resolve our issue, we opted to explore alternative solutions. Our focus shifted towards comprehending the behavior of user-applied filters when executed within a search engine.
A/B testing with real usage traffic
In order to guarantee that our solution effectively addresses the issue at hand, we opted to devise two distinct scenarios utilizing various search engines. This approach aimed to determine the search engine that best aligned with our requirements.
To attain optimal outcomes while preserving consistency, the most effective approach involved the implementation of A/B testing with real usage traffic. This testing methodology aimed to create two distinct endpoints within our backend system, each utilizing a different search engine. Subsequently, upon configuring the endpoints to retrieve data from the respective search engines, we proceeded to modify our frontend interface. The interface was modified to consistently route requests to all available solutions. This change ensured that each filter or action initiated by our end users yielded results so that we could analyze in the future.
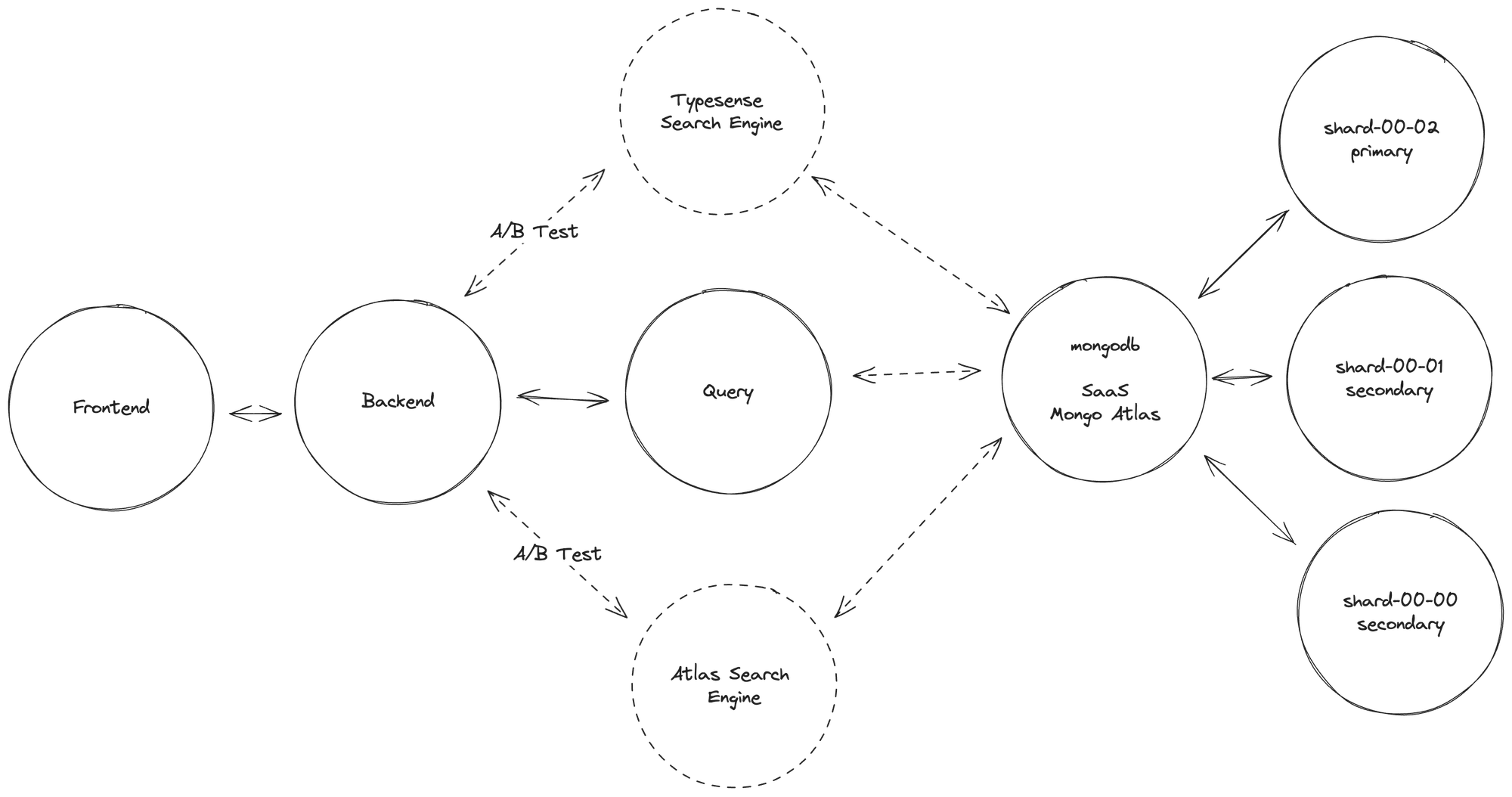
In the image provided, it is evident that each user request for data retrieval and filtering was duplicated across two distinct solutions. This approach was adopted to offer to our client the flexibility of choosing between two scenarios, accompanied by a comprehensive delineation of the respective advantages and drawbacks associated with each option.
We opted to employ Typesense and Atlas Search Engine to present two distinct solutions, despite both addressing the same issue. Atlas Search, included in our client MongoDB subscriptions, eliminates the need for service management. Conversely, we suggested Typesense as a self-hosted alternative, requiring oversight of the service's infrastructure and availability from the infrastructure team.
Upon implementing and deploying this solution in the relevant environments, we revisited the analysis after a few days to review the outcomes from the past three days. The results were remarkable and aligned precisely with our expectations.
The average latency of the requests decreased by approximately 60%, with a reduction of 64.36% using Atlas Search and 56.44% using Typesense. Concurrently, the filters applied by clients falling within the 75th percentile saw a decrease of around 57%, with figures of 57.14% for Atlas Search and 56.57% for Typesense. Notably, a significant enhancement in response time was observed for requests containing intricate details and complex filters, resulting in a remarkable reduction of nearly 98% - specifically, 98.24% using Atlas Search and 97.13% for Typesense.

Load testing
The primary issue stemmed from a lack of foresight regarding the data growth over time by the client. It was imperative for the team not only to address the immediate concern but also to devise a sustainable solution capable of accommodating future data expansion autonomously. The A/B testing instilled confidence to the team regarding the potential of the solution to address our current state-of-the-art challenges. Given our existing engagement with this subject, we opted to delve deeper into the investigation to gain a more comprehensive understanding of the system behavior taking in consideration potential data growth over time.
To deepen our understanding of this topic, we utilized our previous research on vertical scaling of databases as referenced earlier. Subsequently, we chose to index the data in the collections that we created with factors of 2 and 5. We sought to comprehend not only the behavior of the database but also that of our entire infrastructure. Consequently, we opted to conduct load testing on our API, which facilitated the provision of data.
The methodology mirrored previous practices already mentioned in this article, employing suitable requests and filters across all percentiles to analyze metric results encompassing average, minimum, and maximum response times for each potential solution. Subsequently, enhancements were made to the dataset, increasing requests per second to evaluate system performance under heightened data volume and user load.
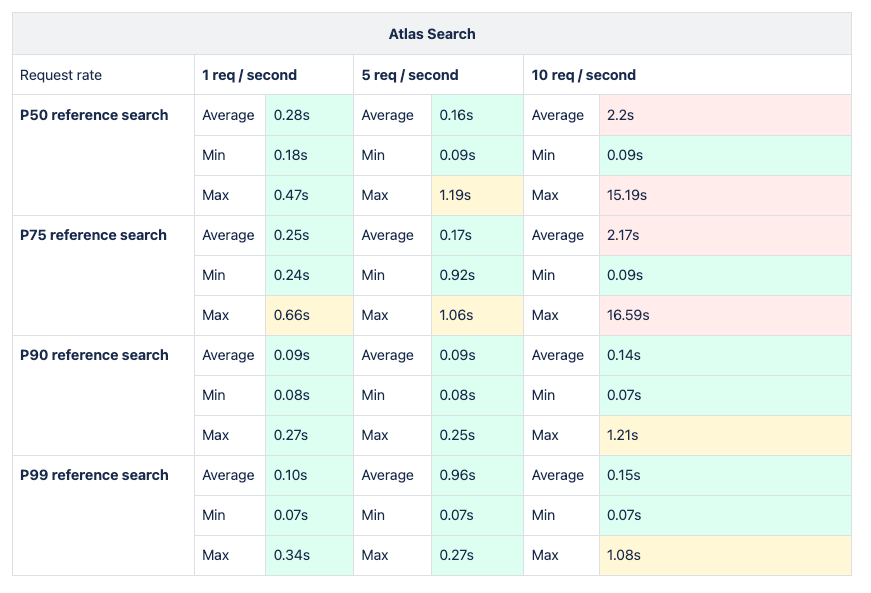
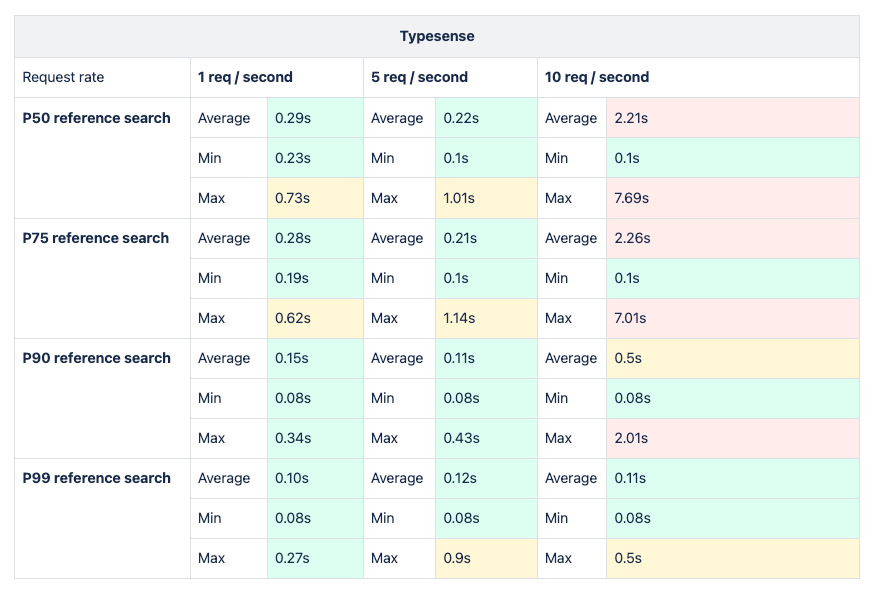
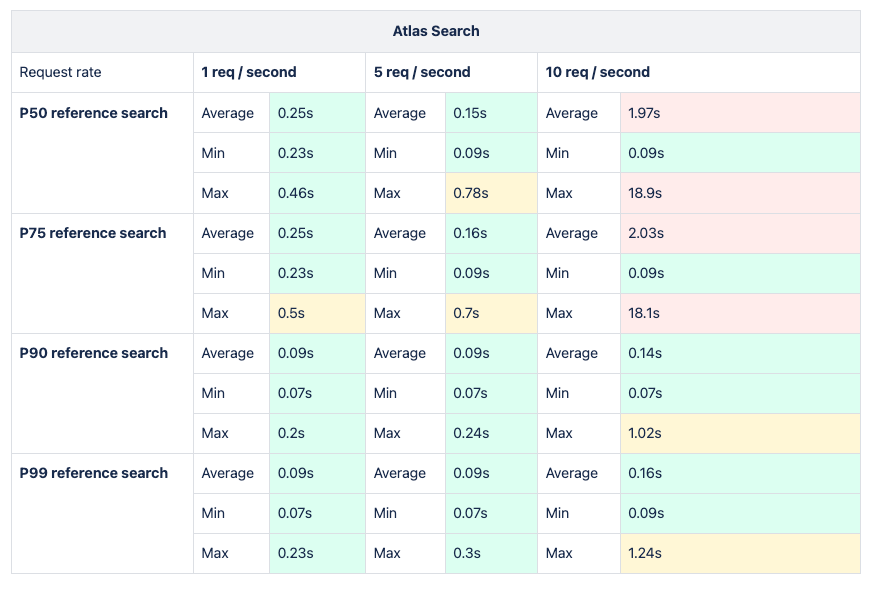
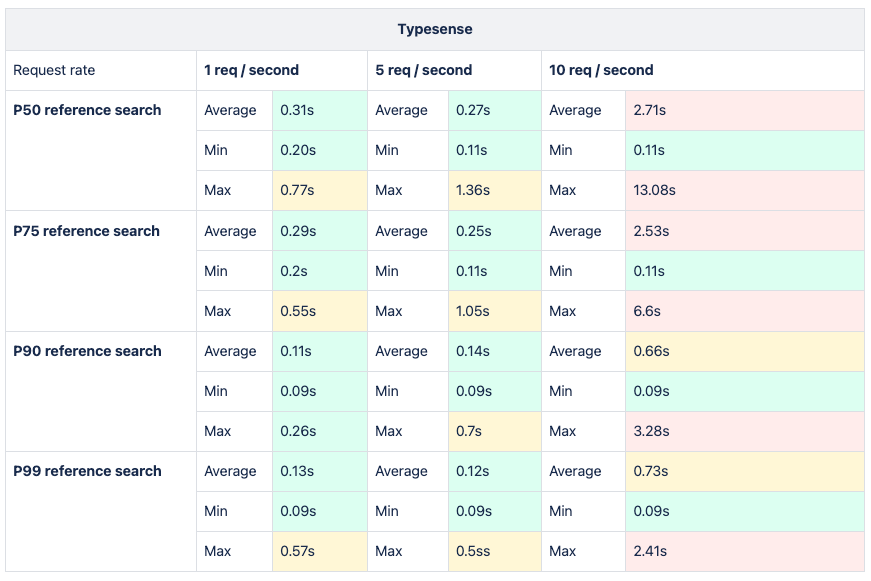
The load testing analysis was conducted utilizing a tool developed by Grafana Labs known as k6s. Grafana is an integral component of the CNCF ecosystem and seamlessly integrates with Cloud Native environments. This robust integration instilled confidence within the team to delve deeper into the tool's capabilities, thereby enhancing the overall investigative process.
Final thoughts
Following an extensive investigation, we successfully identified a viable long-term solution and presented various options to the client, enabling informed decision-making based on data rather than assumptions.
Opting for the Atlas Search solution was deemed optimal due to its integration within the default MongoDB subscription, eliminating the necessity of managing a self-hosted infrastructure. While Typesense also provides a SaaS solution, adopting it would lead to an increase in monthly expenses.
It is imperative to note that both solutions are robust and dependable. When selecting a solution for a similar scenario, it is crucial to assess the suitability for your specific use case, rather than solely relying on the choice made in this article regarding Atlas Search.
At xgeeks, we demonstrated a history of pinpointing successful long-term IT solutions, providing informed decision-making through data-driven options, and streamlining infrastructure management, making us a reliable choice for addressing your current challenges.